Module 1, Practical 7¶
In this practical we will see how to get input from the command line.
Gentle reminder on functions¶
Reminder. The basic definition of a function is:
def function_name(input) :
#code implementing the function
...
...
return return_value
Functions are defined with the def keyword that proceeds the function_name and then a list of parameters is passed in the brackets. A colon : is used to end the line holding the definition of the function. The code implementing the function is specified by using indentation. A function might or might not return a value. In the first case a return statement is used.
Getting input from the command line¶
To call a program my_python_program.py from command line, you just have to open a terminal (in Linux) or the command prompt (in Windows) and, assuming that python is present in the path, you can cd into the folder containing your python program, (eg. cd C:\python\my_exercises\) and just type in python3 my_python_program.py or python my_python_program.py In case of arguments to be passed by command line, one has to put them after the specification of the program name (eg.
python my_python_program.py parm1 param2 param3).
Python provides the module sys to interact with the interpreter. In particular, sys.argv is a list representing all the arguments passed to the python script from the command line.
Consider the following code:
[ ]:
import sys
"""Test input from command line in systest.py"""
if len(sys.argv) != 4: #note that this is the number of params +1!!!
print("Dear user, I was expecting 3 params. You gave me ",len(sys.argv)-1)
exit(1)
else:
for i in range(0,len(sys.argv)):
print("Param {}:{} ({})".format(i,sys.argv[i],type(sys.argv[i])))
Invoking the systest.py script from command line with the command python3 exercises/systest.py 1st_param 2nd 3 will return:
Param 0: exercises/systest.py (<class 'str'>)
Param 1: 1st_param (<class 'str'>)
Param 2: 2nd (<class 'str'>)
Param 3: 3 (<class 'str'>)
Invoking the systest.py script from command line with the command python3 exercises/systest.py 1st_param will return:
Dear user, I was expecting three parameters. You gave me 1
Note that the parameter at index 0, sys.argv[0] holds the name of the script, and that all parameters are actually strings (and therefore need to be cast to numbers if we want to do mathematical operations on them).
Example: Write a script that takes two integers in input, i1 and i2, and computes the sum, difference, multiplication and division on them.
[ ]:
import sys
"""Maths example with input from command line"""
if len(sys.argv) != 3:
print("Dear user, I was expecting 2 params. You gave me ",len(sys.argv)-1)
exit(1)
else:
i1 = int(sys.argv[1])
i2 = int(sys.argv[2])
print("{} + {} = {}".format(i1,i2, i1 + i2))
print("{} - {} = {}".format(i1,i2, i1 - i2))
print("{} * {} = {}".format(i1,i2, i1 * i2))
if i2 != 0:
print("{} / {} = {}".format(i1,i2, i1 / i2))
else:
print("{} / {} = Infinite".format(i1,i2))
Which, depending on user input, should give something like:
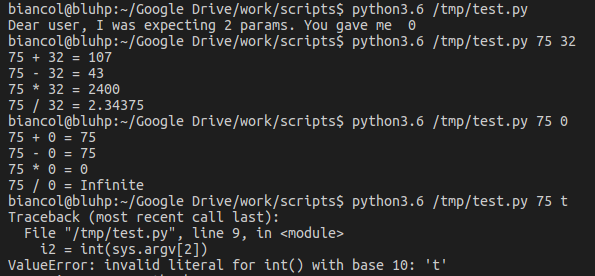
note that we need to check if the values given in input are actually numbers, otherwise the execution will crash (third example). This is easy in case of integers (str.isdigit()) but in case of floats it is more complex and might require Exception handling.
A more flexible and powerful way of getting input from command line makes use of the Argparse module.
Argparse¶
Argparse is a command line parsing module which deals with user specified parameters (positional arguments) and optional arguments.
Very briefly, the basic syntax of the Argparse module (for more information check the official documentation) is the following.
Import the module:
import argparse
Define a argparse object:
parser = argparse.ArgumentParser(description="This is the description of the program")
note the parameter description that is a string to describe the program;
Add positional arguments:
parser.add_argument("arg_name", type = obj,
help = "Description of the parameter)
where arg_name is the name of the argument (which will be used to retrieve its value). The argument has type obj (the type will be automatically checked for us) and a description specified in the helpstring.
Add optional arguments:
parser.add_argument("-p", "--optional_arg", type = obj, default = def_val,
help = "Description of the parameter)
where -p is a short form of the parameter (and it is optional), --optional_arg is the extended name and it requires a value after it is specified, type is the data type of the parameter passed (e.g. str, int, float, ..), default is optional and gives a default value to the parameter. If not specified and no argument is passed, the argument will get the value “None”. Help is again the description string.
Parse the arguments:
args = parser.parse_args()
the parser checks the arguments and stores their values in the argparse object that we called args.
Retrieve and process arguments:
myArgName = args.arg_name
myOptArg = args.optional_arg
now variables contain the values specified by the user and we can use them.
Let’s see the example above again.
Example: Write a script that takes two integers in input, i1 and i2, and computes the sum, difference, multiplication and division on them.
[ ]:
import argparse
"""Maths example with input from command line"""
parser = argparse.ArgumentParser(description="""This script gets two integers in input
and performs some operations on them""")
parser.add_argument("i1", type=int,
help="The first integer")
parser.add_argument("i2", type=int,
help="The second integer")
args = parser.parse_args()
i1 = args.i1
i2 = args.i2
print("{} + {} = {}".format(i1,i2, i1 + i2))
print("{} - {} = {}".format(i1,i2, i1 - i2))
print("{} * {} = {}".format(i1,i2, i1 * i2))
if i2 != 0:
print("{} / {} = {}".format(i1,i2, i1 / i2))
else:
print("{} / {} = Infinite".format(i1,i2))
That returns the following:
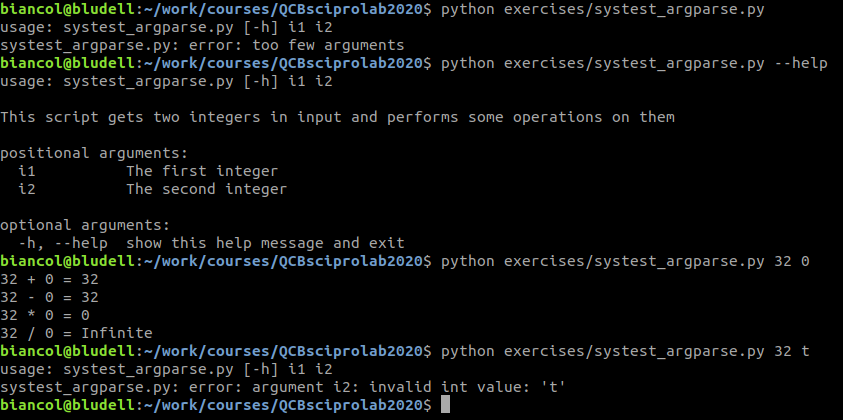
Note that we did not have to check the types of the inputs (i.e. the last time we run the script) but this is automatically done by argparse.
Example: Let’s write a program that gets a string (S) and an integer (N) in input and prints the string repeated N times. Three optional parameters are specified: verbosity (-v) to make the software print a more descriptive output, separator (-s) to separate each copy of the string (defaults to “ “) and trailpoints (-p) to add several “.” at the end of the string (defaults to 1).
[ ]:
import argparse
parser = argparse.ArgumentParser(description="""This script gets a string
and an integer and repeats the string N times""")
parser.add_argument("string", type=str,
help="The string to be repeated")
parser.add_argument("N", type=int,
help="The number of times to repeat the string")
parser.add_argument("-v", "--verbose", action="store_true",
help="increase output verbosity")
parser.add_argument("-p", "--trailpoints", type = int, default = 1,
help="Adds these many trailing points")
parser.add_argument("-s", "--separator", type = str, default = " ",
help="The separator between repeated strings")
args = parser.parse_args()
mySTR = args.string + args.separator
trailP = "." * args.trailpoints
answer = mySTR * args.N
answer = answer[:-len(args.separator)] + trailP #to remove the last separator
if args.verbose:
print("the string {} repeated {} is:".format(args.str, args.N, answer))
else:
print(answer)
Executing the program from command line without parameters gives the message:

Calling it with the -h flag:
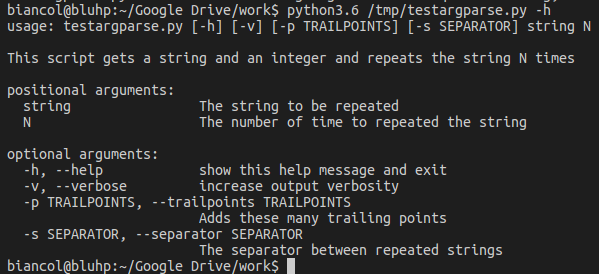
With the positional arguments "ciao a tutti" and 3:

With the positional arguments "ciao a tutti" and 3, and with the optional parameters -s "___" -p 3 -v

Example: Let’s write a program that reads and prints to screen a text file specified by the user. Optionally, the file might be compressed with gzip to save space. The user should be able to read also gzipped files. Hint: use the module gzip which is very similar to the standard file management method (more info here). You can find a text file here textFile.txt and its gzipped version here text.gz:
[ ]:
import argparse
import gzip
parser = argparse.ArgumentParser(description="""Reads and prints a text file""")
parser.add_argument("filename", type=str, help="The file name")
parser.add_argument("-z", "--gzipped", action="store_true",
help="If set, input file is assumed gzipped")
args = parser.parse_args()
inputFile = args.filename
fh = ""
if args.gzipped:
fh = gzip.open(inputFile, "rt")
else:
fh = open(inputFile, "r")
for line in fh:
line = line.strip("\n")
print(line)
fh.close()
The output:

Example: Let’s write a program that reads the content of a file and prints to screen some stats like the number of lines, the number of characters and maximum number of characters in one line. Optionally (if flag -v is set) it should print the content of the file. You can find a text file here textFile.txt:
[ ]:
import argparse
def readText(f):
"""reads the file and returns a list with
each line as separate element"""
myF = open(f, "r")
ret = myF.readlines() #careful with big files!
return ret
def computeStats(fileList):
"""returns a tuple (num.lines, num.characters,max_char.line)"""
num_lines = len(fileList)
lines_len = [len(x.replace("\n", "")) for x in fileList]
num_char = sum(lines_len)
max_char = max(lines_len)
return (num_lines, num_char, max_char)
parser = argparse.ArgumentParser(description="Computes file stats")
parser.add_argument("inputFile", type=str, help="The input file")
parser.add_argument(
"-v", "--verbose", action="store_true", help="if set, prints the file content")
args = parser.parse_args()
inFile = args.inputFile
lines = readText(inFile)
stats = computeStats(lines)
if args.verbose:
print("File content:\n{}\n".format("".join(lines)))
print(
"Stats:\nN.lines:{}\nN.chars:{}\nMax. char in line:{}".format(
stats[0], stats[1], stats[2]))
Output with -v flag:

Output without -v flag:

Libraries installation for the next practicals¶
This section is not mandatory for the current practical, but set the basis for the next ones. For perfoming the next practicals we will need three additional libraries. Try and see if they are already available by typing the following commands in the console or put them in a python script:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
if, upon execution, you do not get any error messages, you are sorted. Otherwise, you need to install them.
In Linux you can install the libraries by typing in a terminal sudo pip3 install matplotlib, sudo pip3 install pandas and sudo pip3 install numpy (or sudo python3.X -m pip install matplotlib, sudo python3.X -m pip install pandas and sudo python3.X -m pip install numpy), where X is your python version.
In Windows you can install the libraries by typing in the command prompt (to open it type cmd in the search box) pip3 install matplotlib, pip3 install pandas and pip3 install numpy. If you are using anaconda you need to run these commands from the anaconda prompt.
Please install them in this order (i.e. matplotlib first, then pandas and finally numpy). You might not need to install numpy as matplotlib requires it. Once done that, try to perform the above imports again and they should work this time around.
Exercises¶
Modify the program of Exercise 6 of Practical 6 in order to allow users to specify the input and output files from command line. Then test it with the provided files. The text of the exercise follows:
Write a python program that reads two files. The first is a one column text file (contig_ids.txt) with the identifiers of some contigs that are present in the second file, which is a fasta formatted file (contigs82.fasta). The program will write on a third, fasta formatted file (e.g. filtered_contigs.fasta) only those entries in contigs82.fasta having identifier in contig_ids.txt.
Show/Hide Solution
have a look to this website sociopattern.org. This cooperation is super cool! they developed a wearable device called sociobadge. Peaple are wearing this badge during some days, and the device collects face-to-face interacions data. On the section data of the website, you find a list of datasets collected in different social context (hospital, primaryschool, highschool, workplaces, conferences, …).
In this exercise we are gona play with those datasets. In particular download the hospital dataset. The dataset is like below:
Time idA idB typeA typeB
For instance.
140 1157 1232 MED ADM
160 1157 1191 MED MED
500 1157 1159 MED MED
520 1157 1159 MED MED
560 1159 1191 MED MED
580 1159 1191 MED MED
you have data separated by a tabular. From the first row we can see that at timestamp 140(seconds) user 1157 talks with 1232, from the same row we know that the user 1157 is a Medical doctor, while user 1232 is works in the amministrative stuff.
1. Write a function that ask the user an id and you have to print either: "the user is not present" or the typer of the user X, for instance: "the user X is an Med/Nurse/Adm/Patient"
2. Write a function that ask the user an id type (Med/Nur/Adm/Pat) and the name of a file (like: "only doctors.txt") and write a new file containing the list of interactions only for that type of user.
3. Print to the scrin the pair of users that has the the maximum number of interaction. for instance, id 10 and id 30 are probablilly friend because the has the the maximum number of interactions among them.
4. **Difficult!**! Do doctors have longer continuous interactions with patients or doctors? Suppose that a doctor is interacting with another doctor for 300 seconds in the first day, but then he talks with the same doctor in another day for 400 seconds. Then the longhest continuous interaction would be 400 seconds. My question is: Do doctor prefer to talk with other doctors or patients? :). You have to compute the longhest interaction among each doctor to doctor and between doctor to patients, then you can answare the question **solution not given**
Show/Hide Solution
Write a python script that takes in input a single-entry .fasta file (specified from the command line) of the amino-acidic sequence of a protein and prints off (1) the total number of aminoacids, (2) for each aminoacid, its count and percentage of the whole. Optionally, it the user specifies the flag “-S” (–search) followed by a string representing an aminoacid sequence, the program should count and print how many times that input sequence appears. Download the Sars-Cov-2 Spike Protein and test your script on it. Please use functions.
Show/Hide Solution
The Fisher’s dataset regarding Petal and Sepal length and width in csv format can be found here. These are the measurements of the flowers of fifty plants each of the two species Iris setosa and Iris versicolor.
The header of the file is:
Species Number,Species Name,Petal width,Petal length,Sepal length,Sepal width
Write a python script that reads this file in input (feel free to hard-code the filename in the code) and computes the average petal length and width and sepal length and width for each of the three different Iris species. Print them to the screen alongside the number of elements.
Show/Hide Solution
1st ML model¶
Machine Learning¶
You’ll explore this in more depth in other courses, but here’s a super simple explanation. You are given a set of data (like images), and each piece of data has a label or category (like “dog” or “cat”). Your goal is to build a model that learns from this data so that, when it sees new, unlabeled data, it can predict the correct label (i.e., whether an image shows a dog or a cat). This process involves training the model on examples to help it make accurate predictions in the future.
In general, your data is split into a training set and a test set (ignoring validation for now). The main idea is to train your model on the training set, where the labels are available, and then evaluate its performance on the test set to see how well it can predict unseen data.

In the image above, you have 9 images to train your model and 2 images to test how well your model performs.
In this lab you have to implement a simple ML model: k-Nearest Neighbors (k-NN)
What is k-Nearest Neighbors (k-NN)?¶
k-Nearest Neighbors (k-NN) is one of the simplest machine learning algorithms used for classification and regression. Here, we’ll focus on using it for classification, which means dividing data into categories (e.g., classifying flowers as different species).
Main Idea Behind k-NN¶
The basic idea behind k-NN is “things that are similar are likely to belong to the same group (or class).” To classify a new data point, we look at the data points closest to it (its “neighbors”). We then decide what class the new data point belongs to based on the majority class among its neighbors.
For instance:¶
You are given the roundness and diameter of both grapes and pears, and your task is to predict whether a fruit is a grape or a pear based on these two features (roundness and diameter). So your input data is something like:
data = [[0.91, 1.1],[0.88, 1.3], [...] ... [0.7,4.2]]
label = [1,1,...,0]
The data includes the roundness and diameter of the fruits, while the label is a list where each value indicates the type of fruit (1 for grape, 0 for pear). For example, the first fruit has a roundness of 0.91 and a diameter of 1.1, and its label is 1, meaning it is a grape.
Now, suppose you have a new fruit with a roundness of 0.82 and a diameter of 2.1. Based on the data, you need to predict whether it’s a grape or a pear. let’s see this with a figure:
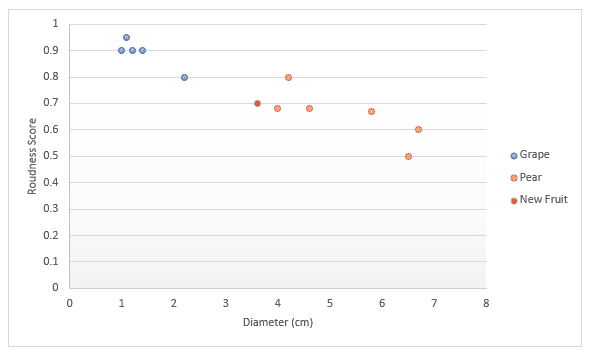
As you can see, grapes (blue points) tend to have a higher roundness and a smaller diameter, which is why the blue points are clustered in the top-left corner of the plot. On the other hand, pears have lower roundness and larger diameter values. Now, suppose a new fruit appears (represented by a red point)—is it a pear or a grape?
K-NN works by selecting the k closest data points (neighbors) to the input based on a distance metric (usually Euclidean distance). Then, it looks at the labels of those k neighbors and assigns the label that appears most frequently (majority vote) to the input. In our case, it would find the k nearest fruits based on roundness and diameter, and classify the new fruit as either a grape or a pear based on the majority label of its closest neighbors.
todo¶
Download the iris dataset from here
load the data and process it to obtain a list of lists i.e.
data = [[7.1, 3.0, 5.9, 2.1],
[5.4, 3.7, 1.5, 0.2],
[5.6, 2.5, 3.9, 1.1],
...]
labels = ['Iris-virginica', 'Iris-setosa', 'Iris-versicolor']
\[d(p, q) = \sqrt{(p_1 - q_1)^2 + (p_2 - q_2)^2 + \dots + (p_n - q_n)^2}\]
Evaluate your model! Compute predictions for the test set and use its label to compute the accuracy
\[\text{Accuracy} = \frac{\text{Number of Correct Predictions}}{\text{Total Number of Predictions}}\]