Laboratorio di Informatica¶
La pagina del corso si trova qui:
mentre quella delle esercitazioni si trova qui:
Hint
Se avete dubbi o domande potete rivolgervi a me:
- Antonio Longa: antonio dot longa at unitn dot it
Siete pregati di usare il tag [INF CIBIO] come oggetto della mail. Es: [INF CIBIO] Errore installazione Virtualbox
Bibliografia¶
- Allen Downey, Think python — How to think like a Computer Scientist, Green Tea Press
- https://github.com/AllenDowney/ThinkPythonItalian/raw/master/thinkpython_italian.pdf
- Lutz, Learning Python (5th edition), O’REILLY, 2013.
Note Introduttive¶
- Assumeremo di lavorare esclusivamente con file di testo, indipendentemente dall’estensione dei file.
- La shell e Python non capiscono le lettere accentate, non usatele.
- Il comportamento di alcuni comandi puo’ variare tra varianti diverse di Unix, ad esempio GNU/Linux e MacOS X.
Virtualbox e Ubuntu¶
Virtualbox¶
Virtualbox è un software gratuito e open source per l’esecuzione di macchine virtuali per architettura x86 e 64bit che supporta Windows, GNU/Linux e macOS come sistemi operativi host, ed è in grado di eseguire diversi sistemi operativi guest come Windows, Linux, OS/2 Warp, OpenBSD, FreeBSD, Solaris etc.
Installazione:
- Scaricate Virtualbox dal seguente link https://www.virtualbox.org/wiki/Downloads nella sezione
VirtualBox 6.1.14 platform packages - Lancite l’eseguibile appena scaricato.
Ubuntu¶
Download di Ubuntu:
- Scaricate Ubuntu dal seguente link https://www.ubuntu-it.org/download
- Sceglite la versione Desktop di Ubuntu 20.04.1 LTS (Long Term Support)
Installazione di Ubuntu su VirtualBox¶
Per poter installare Ubutnu in VirtualBox, vi consiglio di seguire il seguente tutorial https://www.youtube.com/watch?v=x3Zpe1rIPFE
Shell: Fondamentali¶
Cosa faremo oggi?¶

Scorciatoie¶
Alcune dritte per lavorare con la shell:
| combinazione | funzione |
|---|---|
Control-c |
uccide il comando/script in esecuzione |
Tab |
autocompleta comandi e percorsi |
↑, ↓ |
scorrono tra i comandi dati in precedenza |
history |
stampa a schermo la storia dei comandi |
Control-←, Control-→ |
scorrono tra le parole della riga |
Home, End |
saltano all’inizio e alla fine della riga |
Control-l |
pulisce il terminale |
Comando cd¶
Il comando cd permette di muoversi all’interno delle directory.
La sintassi e’:
cd <percorso>
Utilizzando il tasto Tab abbiamo l’autocompletamento dei percorsi!
Il filesystem puo’ essere visto come un albero, simile a questo:
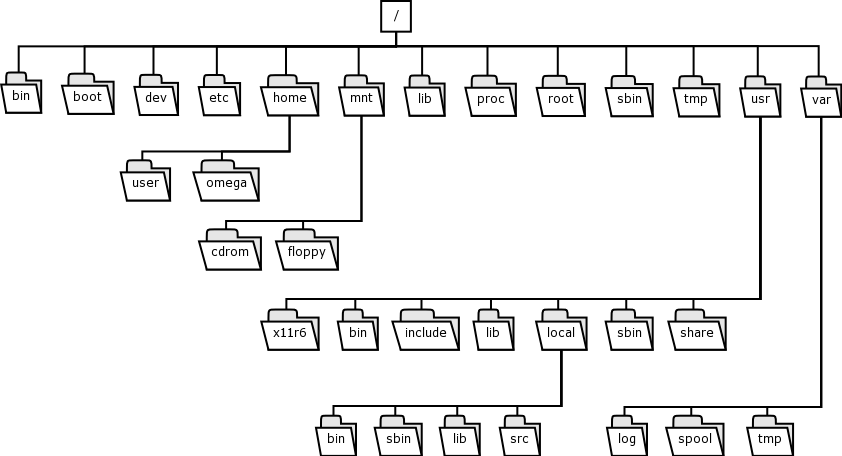
La posizione di ogni file e directory nel filesystem e’ specificata da un percorso (o path).
Utilizzando il comando cd possiamo muoverci nelle varie catelle.
Supponiamo di voler accedere ad una cartella “folder1” il comando da digitare è il seguente:
cd folder1/
Se si vuole risalire nell’albero del filesystem si utilizza il comando:
cd ..
Comando ls¶
Il comando ls permette di visualizzare il contenuto di un folder
La sintassi e’:
ls [-opzioni] <percorso_1> ... <percorso_n>
Il comando ls ha diverse opzioni (che vedremo tra poco), tuttavia
puo’ essere usato senza specificare nessun opzione.
PROVATE VOI:
ls
ls folder1/
OPZIONI
Ci sono diverse opzioni che prmettono di avere un outup piu dettagliato:
| comando | funzione |
|---|---|
ls -l <percorso> |
fornisce un output dettagliato |
ls -s <percorso> |
stampa la dimensione dei file all’interno del percorso |
ls -t <percorso> |
ordina rispetto all’ultima modifica |
ls --help |
stampa la guida del comando ls |
PROVATE VOI:
ls -l
ls -s
ls -t
ls --help
Le opzioni possono essere combinate semplicemnte concatenando piu opzioni:
ls -lst
>> questo comando restituisce la lista dettagliata dei files ordinati e con la dimensione del file.
Comando man¶
Il comando man permette leggere il manuale di un comando
Per invocare un comando man e’ sufficiente scrivere:
man argomento
ESEMPIO:
man ls
Creare un folder¶
Per creare (MaKe DIRectory) una cartella la sintassi e’:
mkdir NomeDelFile
ESEMPIO:
mkdir file1
Spostare un folder¶
Per spostare (MoVe) una cartella la sintassi e’:
mv percorso_file_in percorso_file_out
ESEMPIO:
mv file1 home/antonio/prova/
Il comando mv viene utilizzato anche per rinominare i file, nel segunete modo:
mv file_vecchio_nome file_nuovo_nome
Copiare un folder¶
Per copiare (CoPy) una cartella la sintassi e’:
cp percorso_file_in percorso_file_out
ESEMPIO:
cp file1 home/antonio/prova/
Eliminare un folder¶
Per eliminare (ReMove) una file la sintassi e’:
rm [opzioni] file
Se si vuole eliminare un folder con tutto il suo contenuto è necessario specificare l’opzione -r
ESEMPIO:
mkdir file1
rm -r file1
Esercizi 10 min¶
- Create una catella chiamata “CIBIO”
- All’interno della catella “CIBIO” create una catella “INF” e una cartella “SPROT”
- Create una catella “MOLECOLE” dentro la cartella “INF”
- Rinominate la cartella “SPORT” in “BIOLOGIA”
- Spostate la catella “MOLECOLE” nella cartella “BIOLOGIA”
TRA 10 min invio le soluzioni nella chat
Soluzioni¶
Create una catella chiamata “CIBIO”:
mkdir CIBIO
All’interno della catella “CIBIO” create una catella “INF” e una cartella “SPROT”:
cd CIBIO mkdir INF mkdir SPORTCreate una catella “MOLECOLE” dentro la cartella “INF”:
cd INF mkdir MOLECOLERinominate la cartella “SPORT” in “BIOLOGIA”:
cd .. mv SPORT BIOLOGIASpostate la catella “MOLECOLE” nella cartella “BIOLOGIA”:
mv INF/MOLECOLE/ BIOLOGIA/
Shell: Parte 1¶
Cosa faremo oggi?¶

Creare un File¶
Per poter creare un file, è necessario disporre di un editor di testo, nel nostro caso usermo
nano un editor utilizzabile da terminale
CREARE/APRIRE UN FILE:
nano nome_del_file.txt
Per poter salvare le mofiche appena effettuate premere Ctrl + S, mentre per chiudere l’editro
premere Ctrl + X
PROVATE VOI
Create un file.txt e scriveteci un paio di righe:
nano file.txt
Ciao mi chiamo bla bla bla ...
Ctrl + S
Ctrl + X
Comando cat¶
Il comando cat permette di visualizzare file testuali:
cat file.txt
PROVATE VOI
Ora provate a leggere il file che avete appena scritto.
Il comando cat stampa a video il contenuto di un file, ma questo puo essere reindirizato su un altra sorgente
ad esempio un file:
cat prova.txt > nuova_prova.txt
il comando permette anche di concatenare piu file in un unico file:
nano prova1.txt
nano prova2.txt
cat prova1.txt prova2.txt > concat_prova_1_2.txt
Ora il file concat_prova_1_2.txt contiene la concatenazione dei file prova1 e prova2.
Wildcards¶
La shell esegue quella che si chiama wildcard expansion: ogni volta che
incontra l’asterisco * lo sostituisce con la lista dei file/directory che
“fanno match”.
ESEMPIO. Se eseguo:
ls *
la shell sostituisce * con la lista di tutti i file e le directory nella
directory attuale (perche’ tutti fanno match con *). Invece:
ls informatica/*
sostituisce * con la lista dei file in informatica.
Supponendo che in informatica ci siano solo tre file, chiamati test1,
test2 e results, il comando precedente sarebbe equivalente a:
ls informatica/test1 informatica/test2 informatica/results
Se avessi eseguito:
ls informatica/test*
la wildcard test* avrebbe fatto match solo con test1 e test2, ed
il comando sarebbe stato equivalente a:
ls informatica/test1 informatica/test2
Qui results non fa match, quindi non viene incluso.
Le wildcard piu’ importanti sono:
| wildcard | fa match con |
|---|---|
akz |
il testo “akz” |
* |
una stringa qualunque (anche vuota) |
? |
un carattere qualunque |
[akz] |
un carattere solo tra a, k e z |
[a-z] |
un carattere alfabetico qualunque |
[0-9] |
una cifra qualunque |
[!1b] |
un carattere qualunque che non sia 1 o b |
[!a-e] |
un carattere qualunque che non sia a, b, …, e |
Quando la shell incontra un comando dove uno (o piu’) degli argomenti contiene delle wildacrds, esegue la wildcard expansion: sostituisce all’argomento incriminato tutti i file che fanno match con la wildcard.
Warning
Le wildcards sono simili alle regex, ma non sono la stessa cosa:
- Le wildcards sono usate dalla shell per fare il match di percorsi.
- Le regex sono usate da
grepper fare il match di righe di testo contenute in un file. - Le regole che determinano il match di wildcards e regex sono diverse.
Esempio. La wildcard:
le rose sono *se
fa match con:
le rose sono rosse
ma anche con:
le rose sono costose
e:
le rose sono grosse
ma non con:
i maneggi abitano in montagna
Le wildcard possono essere combinate, ad esempio:
test?[a-z][!0-9]
fa il match con tutti i percorsi che cominciano con test, proseguono con
un carattere qualunque, poi con un carattere alfabetico ed infine con un
carattere non numerico.
Esempio. Un esempio piu’ realistico. Il comando:
cat data/dna-fasta/*.[12]
fa match con tutti i file nella directory data/dna-fasta il cui filename
e’ composto di una-stringa-qualunque, seguita da un punto, seguito da 1 o
2 e nient’altro. Nel nostro caso i soli file a fare match sono:
data/dna-fasta/fasta.1
data/dna-fasta/fasta.2
Dopo la wildcard expansion il comando precedente diventa:
cat data/dna-fasta/fasta.1 data/dna-fasta/fasta.2
PROVATE VOI create le seguenti directory e sub-directory
- data
- data/deep1
- data/deep1/1
- data/deep2
- data/deep2/1
- data/deep3
- data/deep3/1
- data/deep4
- data/deep4/1
Stampare a schermo i contenuti della directory data:
ls data
Per stampare i contenuti delle directory che stanno in data:
ls data/*
Per stampare a schermo solo il contenuto delle directory deep0, …, deep4:
ls data/deep*
Mentre per restringere la wildcard alle directory deep0 e deep3:
ls data/deep[03]
e solo per le directory deep0, …, deep4 ma non deep2:
ls data/deep[!2]
Esercizi 10 min¶
- Create 3 file usando l editor
nano - Copiate i 3 file usando
cpnel folder “prova” - create un quarto file chiamato concat.txt contenente la concatenzione dei 3 file creati
TRA 10 min invio le soluzioni nella chat
Python: Fondamentali¶
Interprete¶
Python si riferisce a:
- il linguaggio Python, un insieme di regole sintattiche e semantiche che definiscono il comportamento di un programma scritto in Python.
- l’interprete
python, un comando eseguibile dalla shell che permette di eseguire codice scritto nel linguaggio Python.
Per far partire l’interprete, da una shell scrivete:
python3
Vi apparira’ una schermata di testo simile a questa:
Python 3.X.X (default, Sep 14 2017, 22:51:06)
[GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
Per eseguire codice python, scrivetelo nell’interprete e date invio, ad esempio:
print("hello, world!")
Per chiudere l’interprete, premete Control-d in una riga vuota.
Tipi¶
Ogni oggetto Python contiene dei dati, questi dati hanno un tipo (un intero, una stringa, una lista, etc.) sui cui operiamo in qualche modo.
I tipi fondamentali sono:
| Tipo | Significato | Valori |
|---|---|---|
bool |
Condizioni | True, False |
int |
Interi | \{-2^{-31},\ldots,2^{31}-1\} |
float |
Razionali | \mathbb{Q} |
str |
Testo | Testo |
list |
Sequenze | Li vedremo più avanti nel corso |
tuple |
Sequenze | Li vedremo più avanti nel corso |
dict |
Mappe | Li vedremo più avanti nel corso |
set |
Insiemi | Li vedremo più avanti nel corso |
Il comando “type()” restituisce il tipo di un oggetto.
Hint
Nei vari esempi che mostrerò, un comando verra mostrato così:
print("ciao")
L’output verra mostrato così:
>> ciao
Aprite un terminale, e digitate:
python3
Provate i seguenti comandi:
type(1)
>> class 'int'
type("ciao")
>> class 'str'
type(1.0)
>> class 'float'
Primi passi con l’interprete¶
Aprite un terminale, e digitate:
python3
Provate i seguenti comandi:
5 + 3
8 / 2
52 * 8
10 % 3
"Ciao" + "come va?"
Tutto molto bello, ma poco utile! Come possiamo fare a memorizzare i risultati… con le Variabili
Variabili¶
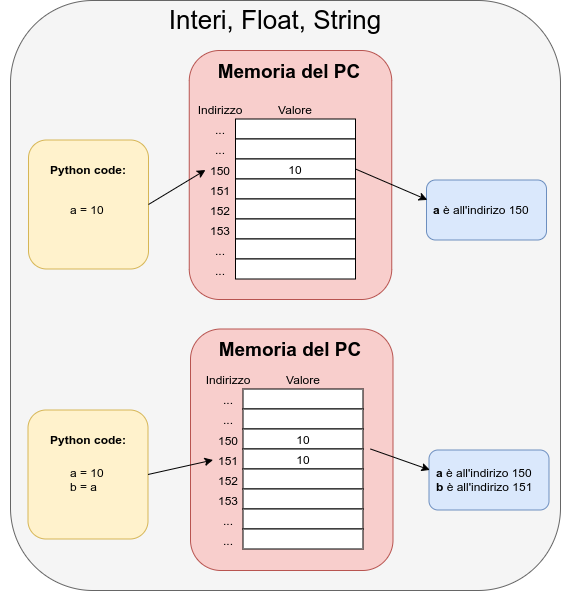
Le variabili sono contenitori di riferimenti ad oggetti. Possono essere viste come nomi per gli oggetti a cui si riferiscono.
Perche dico riferimenti?
nel caso di Stringe Interi Float Boolean …
nel caso di strutture un po’ più complesse
Un oggetto viene assegnato ad una variabile con =:
pi = 3.1415926536
Qui la variabile di nome pi si riferisce all’oggetto 3.1415926536 di
tipo float. In sostanza abbiamo deciso che pi e’ un nome per l’oggetto
3.1415926536.
Warning
Il nome della variabile e’ arbitrario!
Lo decidiamo noi in modo che sia conveniente: breve, descrittivo degli oggetti a cui si riferisce, indicativo del ruolo che la variabile svolge nel nostro codice, etc.
Il tipo di una variabile e’ il tipo dell’oggetto a cui si riferisce. Ne segue
che il tipo di pi e’ float.
Warning
La variabile non contiene l’oggetto, ma un riferimento a quell’oggetto.
Per stampare il valore di una variabile, uso la funzione print:
variabile = "sono una esempio"
print(variabile)
Per stampare il tipo di una variabile, uso la funzione type:
variabile = "sono un esempio"
print(type(variabile))
Esempio. Creo una nuova variabile var:
var = 123
Il nome di var e’ var, il suo valore e’ 123, il suo tipo e’ int.
Esempio. Una variabile puo’ essere assignata piu’ volte:
var = 1
var = "MANLFKLGAENIFLGRKAATKEEAIRF"
var = 3.1415926536
Il nome della variabile resta sempre lo stesso, ma tipo e valore cambiano ad
ogni passaggio: controlla con print(var) e print(type(var)).
Documentazione¶
Per visualizzare l’aiuto di un tipo/oggetto/variabile, usa la funzione help,
ad esempio:
help(123)
visualizza l’aiuto degli interi, cioe’ del tipo dell’oggetto 123. Avrei
ottenuto lo stesso risultato con:
x = 123
help(x)
o:
help(int)
L’aiuto si usa come il manuale della shell: posso navigare l’aiuto con le
frecce, cercare un termine con /, e chiudere l’aiuto con q.
Esercizio insieme¶
Calcola il Body Mass Index BMI, prendendo in input peso(kg) ed altezza(m). Usando la seguente formula
BMI = peso / (altezza * altezza)
definiamo le variabili peso e altezza:
peso = 70
altezza = 1.75
calcoliamo il BMI e mettiamolo in una variabile:
BMI = peso / (altezza * altezza)
stampiamo il BMI:
print("il suo BMI è ",BMI)
Esercizi¶
- Calcola il perimetro di un triangolo, con i seguenti lati lato1 = 10,lato2 = 20, lato3 = 50
- Prendi tre variabili di tipo stringa e stampa la loro somma(+).
- Riscrivi il programma per calcolare il BMI e stampa il tipo di peso, altezza e BMI.
- Cerca il metodo split nella documentazione del tipo string (str), successivamente utilizza lo split sulla variabile prova di tipo str contenente “Ciao Come va? Io sto bene” con separatore (sep) = ” “
Soluzioni¶
Calcola il perimetro di un triangolo, con i seguenti lati lato1 = 10,lato2 = 20, lato3 = 50:
lato1 = 10 lato2 = 20 lato3 = 50 perimetro = lato1 + lato2 + lato3 print("Il perimetro è: ",perimetro)
Prendi tre variabili di tipo stringa e stampa la loro somma(+).:
stringa1 = "ciao " stringa2 = "come ti chiami" stringa3 = "?" sum = stringa1 + stringa2 + stringa3 pritn("la concatenazione di:") pritn(stringa1,stringa2,stringa3) print("è ugauale a:", sum)
Riscrivi il programma per calcolare il BMI e stampa il tipo di peso, altezza e BMI.:
peso = 60 altezza = 100
BMI = peso / (altezza * altezza)
print(“il type di peso è”,type(peso)) print(“il type di altezza è”,type(altezza)) print(“il type di BMI è”,type(BMI))
Cerca il metodo split nella documentazione del tipo string (str), successivamente utilizza lo split sulla variabile prova di tipo str contenente “Ciao Come va? Io sto bene” con separatore (sep) = ” “:
help(str) # premi / per cercare # cerca "split" # leggi come utilizzare lo split prova = "Ciao Come va? Io sto bene" print(prova.split(sep=" ")) >>> ["Ciao","Come","va?","Io","sto","bene"]
Python: Moduli¶
Interprete Python¶
Le scorse volte abbiamo lavorato con l’interprete Python, è stato divertente ma poco utile.
A cosa serve l’interprete
- Testare funzioni del quale non ricordimo il funzionamento
- Interrogare la documentazione
- Testare il codice che abbiamo scitto
- Eseguire python in tempo reale (es interrogare database, inviare pacchetti in rete, etc…)
Moduli¶
Un’alternativa all’eseguire codice nell’interprete e’ scrivere un modulo: un
file di testo con estensione .py in cui scrivete il codice da eseguire.
Warning
L’estensione .py e’ obbligatoria!
Per scrivere un modulo, diciamo il file eseguibile.py, devo aprire un editro di testo (es nano, gedit, notepad++ etc),
scrivere il codice python e salvarlo:
eseguibile.py
Per eseguire un modulo, diciamo il file eseguibile.py, scrivo dalla shell:
python eseguibile.py
PROVATE VOI
- Create un file prova.py
- Scrive un semplice programma che fa la somma di 2 numeri e stampate il risultato.
- Lanciate il programa apppena scritto.
Per utilizzare le funzioni definite in un modulo all’interno di un altro, uso
import. Ad esempio, se in eseguibile.py voglio usare la funzione
ordina_proteine() precedentemente definita nel modulo util.py, scrivo
all’inizio di eseguibile.py:
import util
Warning
Quando importate un modulo, omettete l’estensione .py.
A questo punto posso usare ordina_proteine() cosi’:
util.ordina_proteine()
Warning
I contenuti di un modulo importato vengono prefissati col nome del modulo:
qui abbiamo invocato util.ordina_proteine, non ordina_protein liscio.
Esercizi¶
- Create un modulo che calcola i BMI.
- Create un modulo che stampi una frase.
Soluzioni¶
Create un modulo che calcola i BMI.
Aprite un editor di testo Scrivete il seguente codice:
peso = 50 altezza = 160 BMI = peso /(altezza * altezza) print(BMI)
Aprite una shell, raggingete il precorso dove è stato salvato il file ed eseguitelo
Create un modulo che stampi una frase.
Aprite un editor di testo Scrivete il seguente codice:
testo = "Ciao come va" print(testo)
Aprite una shell, raggingete il precorso dove è stato salvato il file ed eseguitelo
Python: Numeri¶
Numeri: Tipi Fondamentali¶
Ci sono tre tipi numerici fondamentali:
| Tipo | Significato |
|---|---|
int |
Rappresenta numeri interi (!) |
float |
Rappresenta numeri razionali a virgola mobile (float ing-point) |
bool |
Rappresenta condizioni, puo’ essere True o False |
Note
I razionali float hanno precisione limitata: la maggior parte dei
razionali puo’ essere rappresentata solo approssimatamente con un
float.
Ai fini di questo corso, i dettagli non sono importanti.
Esempio. Creo tre variabili, una per tipo, poi le stampo a schermo con
print:
n = 10
x = 3.14
cond = False
# Stampo le tre variabili
print(n, x, cond)
# Idem, inframezzando testo
print("n =", n, "x =", x, "e la condizione cond vale", cond)
Questa sintassi di print vale per tutti i tipi di variabili, non solo
quelli numerici.
Numeri: Aritmetica¶
Tutti i tipi numerici mettono a disposizione le stesse operazioni aritmetiche:
| Operazione | Significato |
|---|---|
a + b |
somma |
a - b |
differenza |
a * b |
prodotto |
a / b |
divisione |
a // b |
divisione intera |
a % b |
resto della divisione (o modulo) |
a ** b |
elevamento a potenza |
Il tipo del risultato di n operazione m e’ automaticamente il tipo
piu’ “complesso” tra i tipi di n e m – per questo si parla di
conversione automatica.
La scala di complessita’ dei tipi numerici e’:
bool < int < float
Esempio. Ad esempio, se sommo un int ed un float, otterro’ un
float:
risultato = 1.2 + 1 # float * int
print(risultato) # 1.2
print(type(risultato)) # float
Questo perche’ e’ necessario un float per rappresentare il valore 1.2:
un int non basterebbe!
Warning
Per evitare errori, e’ necessario scegliere il tipo delle variabili in modo che il tipo del risultato sia sufficientemente “complesso” da riuscire a rappresentarne il valore.
Numeri: Confronti¶
Tutti i tipi numerici (e in generale tutto i tipi Python che vedremo durante il corso) supportano le operazioni di comparazione:
| Operazione | Significato |
|---|---|
a == b |
uguale |
a != b |
diverso |
a < b |
minore |
a <= b |
minore o uguale |
a > b |
maggiore |
a >= b |
maggiore o uguale |
Il risultato di un’espressione di confronto e’ sempre un bool: vale
True se la condizione e’ soddisfatta, e False altrimenti.
Esempio. Aritmetica e confronti possono essere combinati per verificare condizioni “complesse”, come questa:
na, nc, ng, nt = 2, 6, 50, 4
risultato = (na + nt) > (nc + ng)
print(risultato)
print(type(risultato))
I valori Booleani bool (es. i risultati delle operazioni di confronto)
possono essere combinati attraverso le operazioni logiche:
| Operazione | Significato |
|---|---|
a and b |
congiunzione: True se e solo se a e b sono True |
a or b |
disgiunzione: True se almeno una tra a e b e’ True |
not a |
negazione: True se a e’ False e viceversa |
Qui sia a che b sono dei bool.
Warning
In generale, fare aritmetica (es. somme) con valori Booleani e costruire espressioni logiche con valori interi o razionali e’ sconsigliato.
In questi casi, Python si comporta in modo (deterministico e spiegabile, ma decisamente) bizzarro.
Esempio. x > 12 e x < 34 danno come risultato dei bool, quindi
le posso combinare per ottenere:
# int int
# | |
print((x > 12) and (x < 34))
# \______/ \______/
# bool bool
# \___________________/
# bool
oppure:
# int int
# | |
print((not (x > 12)) or (x < 34))
# \______/
# bool
# \____________/ \______/
# bool bool
# \________________________/
# bool
Esempi¶
Esempio. Calcolo gli zeri dell’equazione quadratica x^2 - 1 = 0:
a, b, c = 1.0, 0.0, -1.0
delta = b**2 - 4*a*c
zero1 = (-b + delta**0.5) / (2 * a)
zero2 = (-b - delta**0.5) / (2 * a)
print(zero1, zero2)
Qui uso x**0.5 per calcolare la radice quadrata: \sqrt{x} = x^\frac{1}{2}.
Esempio. Voglio calcolare il GC-content di un gene. So che il gene:
- E’ lungo 1521 basi.
- Contiene 316 citosine.
- Contiene 235 guanine.
Simbolicamente, il GC-content e’ definito come (g + c) / n. Per calcolarlo posso scrivere:
n, c, g = 1521, 316, 235
gc_content = (c + g) / n
print(gc_content)
Esempio. Per controllare che x (il cui valore e’ “fuori dal mio
controllo”, ma nell’esempio sotto fisso per convenienza) cada nell’intervallo A
= [10,50] scrivo:
x = 17 # ad esempio
minimo_a, massimo_a, x = 10, 50
dentro_a = (minimo_a <= x <= massimo_a)
print(dentro_a)
oppure:
dentro_a = ((x >= minimo_a) and (x <= massimo_a))
Assumendo che dentro_a, dentro_b e dentro_c indichino che x e’
nell’intervallo A, B o C, rispettivamente, posso comporre condizioni piu’
complesse:
# x e' in almeno uno dei tre intervalli
dentro_almeno_uno = dentro_a or dentro_b or dentro_c
# x e' sia in A e B, ma non in C
dentro_a_e_b_ma_non_c = dentro_a and dentro_b and (not dentro_c)
Esercizi¶
Creare alcune variabili, controllando ad ogni passaggio che valore e tipo siano corretti (usando
printetype):aebcon valore12e23come interi.xeycon valore21e14come razionali.
Usando
print(una sola volta), stampare:- Tutte le variabili di cui sopra sulla stessa riga.
- Tutte le variabili di cui sopra, separate da
;, sulla stessa riga. - Il testo “il prodotto di
aebe’a * b”, sostituendo ada,bea * bi valori delle variabili.
Determinare valore e tipo di:
- Il prodotto di
aeb. - Il quoziente di
xey. - Il quoziente intero di
aeb. - Il quoziente intero di
xey. - Il prodotto di
bey. 2elevato a0.2elevato a1.2.2elevato a-2.- La radice quadrata di
4. - La radice quadrata di
2.
- Il prodotto di
Che differenza c’e’ tra:
10 / 1210 / 12.010 // 1210 // 12.0
Che differenza c’e’ tra:
10 % 310 % 3.0
Usando
pi = 3.141592e dator = 2.5, calcolare:- La circonferenza di raggio
r: 2 \pi r. - L’area di un cerchio di raggio
r: \pi r^2. - Il volume di una sfera di raggio
r: \frac{4}{3} \pi r^3.
- La circonferenza di raggio
Creare due variabili
a = 100eb = True. Usando un numero opportuno di variabili ausiliarie (chiamatele come volete!), fate in modo che il valore diafinisca inbe che quello dibfinisca ina.(Scrivere
a = Trueeb = 100non vale!)Si puo’ fare con una sola variabile ausiliaria?
Sullo stesso strand di DNA si trovano due geni. Il primo include i nucelotidi dalla posizione 10 alla posizione 20, il secondo quelli dalla posizione 30 alla posizione 40. Scriviamo queste informazioni cosi’:
gene1_inizio, gene1_fine = 10, 20 gene2_inizio, gene2_fine = 30, 40
Data una variabile
posche rappresenta una posizione arbitraria sullo strand, scrivere dei confronti per verificare se:possi trova nel primo gene.possi trova nel secondo gene.possi trova tra l’inizio del primo gene e la fine del secondo.possi trova tra l’inizio del primo gene e la fine del secondo, ma in nessuno dei due geni.possi trova prima dell’inizio del primo gene o dopo la fine del secondo.poscade in uno dei due geni.posnon dista piu’ di 10 dall’inizio del primo gene.
Date le tre variabili Booleane
t,u, ev, scrivere delle espressioni che valgonoTruese e solo se:t,u,vtutte e tre vere.te’ vera oppureue’ vera, ma non entrambe.- Esattamente una delle tre variabili e’ falsa.
- Esattamente una delle tre variabili e’ vera.
Soluzioni¶
Soluzioni:
a = 12 b = 23 print(a, b) print(type(a), type(b)) # int, int x = 21.0 y = 14. print(x, y) print(type(x), type(y)) # float, float
Soluzioni:
print(a, b, x, y) print(a, ";", b, ";", x, ";", ...)
Soluzioni:
# casi semplici: prodotto = a * b # int * int print(prodotto) print(type(prodotto)) # int # divisione e divisione intera tra vari # tipi di numeri: quoziente = x / y # float / float print(quoziente) print(type(quoziente)) # float risultato = a // b # int // int print(risultato) print(type(risultato)) # int risultato = x // y # float // float print(risultato) print(type(risultato)) # float risultato = b * y # int * float print(risultato) print(type(risultato)) # float # qui il tipo e' determinato automaticamente # in base alla magnitudine del risultato: risultato = 2**0 # int**int print(risultato) print(type(risultato)) # int risultato = 2**1.2 # int*float print(risultato) print(type(risultato)) # float risultato = 2**-2 # int*int print(risultato) print(type(risultato)) # *** float!!! *** risultato = 4**0.5 # int*float print(risultato) print(type(risultato)) # float risultato = 2**0.5 # int*float print(risultato) print(type(risultato)) # float
Soluzioni:
>>> print(10 / 12) 0.8333333333333334 >>> print(10 / 12.0) 0.8333333333333334 >>> print(10 // 12) 0 >>> print(10 // 12.0) 0.0
Come si vede la divisione intera si comporta normalmente rispetto ai tipi: quando la applico ai due float il risultato e’ quello della divisione normale, ma troncato all’intero
0.Soluzioni:
>>> 10 % 3 1 >>> 10 % 3.0 1.0
Come si puo’ vedere,
%ritorna il resto di10 / 3:10 = 3*3 + 1 # ^ # il resto
Il tipo degli operandi non influenza il valore del risultato, solo il suo tipo.
Soluzione:
pi = 3.141592 r = 2.5 circonferenza = 2 * pi * r print(circonferenza) area = 2 * pi * r**2 print(area) area = 2 * pi * r * r print(area) volume = (4.0 / 3.0) * pi * r**3 print(volume)
Soluzione:
a, b = 100, True a2 = a b2 = b b = a2 a = b2 print(a, b)
oppure:
a, b = 100, True x = a a = b b = x print(a, b)
Soluzione:
gene1_inizio, gene1_fine = 10, 20 gene2_inizio, gene2_fine = 30, 40 # disegnino: # # 5' 3' # ~~~~~xxxxxxxx~~~~~xxxxxxx~~~~~> # 10 20 30 40 # \______/ \_____/ # gene_1 gene_2 # due alternative condizione_1 = (10 <= pos <= 20) condizione_1 = (pos >= 10 and pos <= 20) condizione_2 = (30 <= pos <= 40) condizione_3 = (10 <= pos <= 40) # due alternative condizione_4 = condizione_3 and not (condizione_1 or condizione_2) condizione_4 = (20 <= pos <= 40) condizione_5 = pos < 10 or pos > 40 # occhio che: # # pos < 10 and pos > 40 # # non ha senso: e' sempre False! condizione_6 = condizione_1 or condizione_2 condizione_7 = (0 <= pos <= 20)
Il codice va testato con diversi valori di
posizione, in modo da controllare che le condizioni si comportino come vogliamo: che sianoTruequando la posizione soddisfa i requisiti della domanda, eFalsealtrimenti.Soluzione:
tutte_e_tre = t and u and v t_oppure_u_ma_non_tutte_e_due = (t or u) and not (t and u) # NOTA: qui i backslash alla fine delle righe servono # per andare "a capo", potete ignorarli. una_delle_tre_falsa = \ (t and u and not v) or \ (t and not u and v) or \ (not t and u and v) una_delle_tre_vera = \ (t and not u and not v) or \ (not t and u and not v) or \ (not t and not u and v)
Di nuovo, il codice va testato usando diversi valori per
t,uev. Ci sono 8 combinazioni in tutto:t, u, v = False, False, False t, u, v = False, False, True t, u, v = False, True, False t, u, v = False, True, True # ...
Python: Stringhe¶
Le stringhe sono oggetti immutabili che rappresentano testo.
Per definire una stringa, ho due alternative equivalenti:
var = "testo"
var = 'testo'
Per creare una stringa multilinea posso inserire manualmente i carattere di
a capo \n in ogni riga:
sad_joke = "Time flies like an arrow.\nFruit flies like a banana."
print(sad_joke)
oppure usare le triple virgolette:
sad_joke = """Time flies like an arrow.
Fruit flies like a banana."""
print(sad_joke)
PROVATE VOI:
- Create una variabile con il vostro nome e cognome. ES: name=”Antonio Longa”
- Usate entrambe le virgolette (“” e ‘’), Cosa cambia? se stampate il type cosa cambia?
- Ora create una variabile multilinea con il vostro nome e cognome.
Conversioni Stringa-Numero¶
Posso convertire un numero in una stringa usando str():
n = 10
print(n, type(n))
s = str(n)
print(s, type(s))
int() o float() fanno l’esatto opposto:
n = int("123")
print(n, type(n))
q = float("1.23")
print(q, type(q))
Warning
Se la stringa non descrive un numero del tipo giusto, Python da’ errore:
int("3.14") # Non e' un int
float("giardinaggio") # Non e' un numero
int("1 2 3") # Non e' un numero
int("fifteen") # Non e' un numero
PROVATE VOI:
- Crate 4 variabili
- nome = vostro nome di tipo string
- cognome = vostro cognome di tipo string
- eta = vostra eta di tipo int
- altezza = vostra altezza di tipo float
- Convertite tutto in stringa e stampate la concatenzaione (+).
Operazioni¶
| Ritorna | Operatore | Significato |
|---|---|---|
int |
len(str) |
Restituisce la lunghezza della stringa |
str |
str + str |
Concatena le due stringhe |
str |
str * int |
Replica la stringa |
bool |
str in str |
Controlla se una stringa appare in un’altra |
str |
str[int:int] |
Estrae una sotto-stringa |
Esempio. Concateno due stringhe:
stringa = "una" + " " + "stringa"
lunghezza = len(stringa)
print("la stringa:", stringa, "e' lunga", lunghezza)
Un altro esempio:
stringa = "basta Python!" * 1000
print("la stringa e' lunga", len(stringa), "caratteri")
Warning
Non posso concatenare stringhe con altri tipi. Ad esempio:
var = 123
print("il valore di var e'" + var)
da’ errore. Due alternative funzionanti:
print("il valore di var e'" + str(var))
oppure:
print("il valore di var e'", var)
(Nel secondo caso manca uno spazio tra e' e 123.)
PROVATE VOI
- Crate 3 variabili
- nome = vostro nome di tipo string
- cognome = vostro cognome di tipo string
- eta = vostra eta di tipo int
- Stampate il vostro nome età volte, stmpate il vostro cognome un numero di volte uguale alla metà dei vostri anni. Es: se avete 4 anni, il risultato sarà “AntonioAntonioAntonioAntonio” e “LongaLonga”
- Cosa succede se avete un età dispari? :)
Esempio. L’operatore sottostringa in stringa controlla se
sottostringa appare una o piu’ volte in stringa, ad esempio:
stringa = "A beautiful journey"
print("A" in stringa) # True
print("beautiful" in stringa) # True
print("BEAUTIFUL" in stringa) # False
print("ul jour" in stringa) # True
print("Gengis Khan" in stringa) # False
print(" " in stringa) # True
print(" " in stringa) # False
Il risultato e’ sempre True o False.
PROVATE VOI
- Dato il seguente frammento di DNA
- DNA = “acactcgagacaatcttggtatcggtctacgcctcgcatcgattaggtgattgtggagcgt
- cgggagtatggtatcaagcgaacttaatcctttatgtaaaggcgctttggatctttgaaga ccagccacgtgcccgctgaccgacagctcagaacataacacgttggtcgttacccggctaa gcgaaaacgggatggggcgtcgcttcggattacccgattctgaatattcgtgtaagcattg cccgtacatttgtgactatatgagtaggaacgaccttgcgtccaaagaagtttagttggtt caacgaattaacagcctagcacatagctaagtacgtcggttcatatggcccctcaccataa”
- Cercate se contiene le seguenti sottostringhe
- atcgattaggtgattgtggagcgtcggg
- atcg
- ggggg
- ATCG
Esempio. Per estrarre una sottostringa si usa l’indicizzazione:
# 0 -1
# |1 -2|
# ||2 -3||
# ||| ... |||
alfabeto = "abcdefghijklmnopqrstuvwxyz"
print(alfabeto[0]) # "a"
print(alfabeto[1]) # "b"
print(alfabeto[len(alfabeto)-1]) # "z"
print(alfabeto[len(alfabeto)]) # Errore
print(alfabeto[10000]) # Errore
print(alfabeto[-1]) # "z"
print(alfabeto[-2]) # "y"
print(alfabeto[0:1]) # "a"
print(alfabeto[0:2]) # "ab"
print(alfabeto[0:5]) # "abcde"
print(alfabeto[:5]) # "abcde"
print(alfabeto[-5:-1]) # "vwxy"
print(alfabeto[-5:]) # "vwxyz"
print(alfabeto[10:-10]) # "klmnop"
Warning
L’estrazione e’ inclusiva rispetto al primo indice, ma esclusiva rispetto
al secondo. In altre parole alfabeto[i:j] equivale a:
alfabeto[i] + alfabeto[i+1] + ... + alfabeto[j-1]
Notate che alfabeto[j] e’ escluso.
Warning
Occhio che l’estrazione restituisce una nuova stringa, lasciando l’originale invariata:
alfabeto = "abcdefghijklmnopqrstuvwxyz"
sottostringa = alfabeto[2:-2]
print(sottostringa)
print(alfabeto) # Resta invariato
PROVATE VOI
- Usate il DNA definito prima.
- Create una variabile (ultimi10) contenente gli ultimi 10 caratteri del DNA
- Create una variabile (primi30) contenente i primi 30 caratteri del DNA
- Create una terza variabile (var) contenente la concatenazione delle variabili ultimi10 e primi30 ripetuta 10 volte.
- Cercate all’interno della variabile var la stringa agct.
Metodi¶
oggetto.metodo(parametri)
| Ritorna | Metodo | Significato |
|---|---|---|
str |
str.upper() |
Restituisce la stringa in maiuscolo |
str |
str.lower() |
Restituisce la stringa in minuscolo |
str |
str.strip(str) |
Rimuove stringhe ai lati |
str |
str.lstrip(str) |
Rimuove stringhe a sinistra |
str |
str.rstrip(str) |
Rimuove stringhe a destra |
bool |
str.startswith(str) |
Controlla se la stringa comincia per un’altra |
bool |
str.endswith(str) |
Controlla se la stringa finisce per un’altra |
int |
str.find(str) |
Restituisce la posizione di una sotto-stringa |
int |
str.count(str) |
Conta il numero di ripetizioni di una sotto-stringa |
str |
str.replace(str, str) |
Rimpiazza sotto-stringhe |
Warning
Proprio come l’estrazione, i metodi restituiscono una nuova stringa, lasciando l’originale invariata:
alfabeto = "abcdefghijklmnopqrstuvwxyz"
alfabeto_maiuscolo = alfabeto.upper()
print(alfabeto_maiuscolo)
print(alfabeto) # Resta invariato
Esempio. upper() e lower() sono molto semplici:
testo = "no yelling"
risultato = testo.upper()
print(risultato)
risultato = risultato.lower()
print(risultato)
Esempio. Le varianti di strip() lo sono altrattanto:
testo = " un esempio "
print(testo.strip()) # equivale a testo.strip(" ")
print(testo.lstrip()) # equivale a testo.lstrip(" ")
print(testo.rstrip()) # equivale a testo.rstrip(" ")
print(testo) # testo e' invariato
Notate che lo spazio tra "un" ed "esempio" non viene mai rimosso. Posso
passare piu’ di un carattere da rimuovere:
"AAAA un esempio BBBB".strip("AB")
PROVATE VOI
- prendete i primi 100 caratteri del DNA definito in precedenza, salvateli in una variabile chiamata sequenza.
- mettete tutto in maiuscolo
- rimuovete le “a” all’inizio e alla fine.
- qunato è lunga la nuova stringa?
Esempio. Lo stesso vale per startswith() e endswith():
testo = "123456789"
print(testo.startswith("1")) # True
print(testo.startswith("a")) # False
print(testo.endswith("56789")) # True
print(testo.endswith("5ABC9")) # False
Esempio. find() restituisce la posizione della prima occorrenza di
una sottostringa, oppure -1 se la sottostringa non appare mai:
testo = "123456789"
print(testo.find("1")) # 0
print(testo.find("56789")) # 4
print(testo.find("Q")) # -1
Esempio. replace() restituisce una copia della stringa dove una
sottostringa viene rimpiazzata con un’altra:
testo = "se le rose sono rosse allora"
print(testo.replace("ro", "gro"))
Esempio. Data la stringa “sporca” di aminoacidi:
sequenza = ">MAnlFKLgaENIFLGrKW "
voglio sbarazzarmi del carattere ">", degli spazi, e poi convertire
il tutto in maiuscolo per uniformita’:
s1 = sequenza.lstrip(">")
s2 = s2.rstrip(" ")
s3 = s2.upper()
print(s3)
In alternativa, tutto in un passaggio:
print(sequenza.lstrip(">").rstrip(" ").upper())
Perche’ funziona? Riscriviamolo con le parentesi:
print(( ( sequenza.lstrip(">") ).rstrip(" ") ).upper())
\_____________________/
str
\_____________________________________/
str
\_____________________________________________/
str
Come vedere, il risultato di ciascuno metodo e’ una stringa, proprio come
sopra lo erano s1, s2 e s3; e su queste posso invocare i metodi
delle stringhe.
Esercizio insieme¶
- Considerando la segente stringa in input: DNA = “ttggtatcggtctacgcctcgcatcgattaggtgattgtgga”
- Convertiamo la stringa in maiuscolo.
- Contiamo le occorrenze di timina, guanina, citosina e adenina, salvandole in variabili con nomi opportuni.
- Stampiamo la media delle loro frequnze
- Quante volte compare il codone “ttg”?
- Convertiamo la sequenza del DNA in forma estesa. cioè: t diventa timina, g diventa guanina etc etc etc
Esercizi¶
Come faccio a:
Creare una stringa che abbia, come testo, cinque spazi.
Controllare che una stringa contenga almeno uno spazio.
Controllare che una stringa contenga cinque caratteri.
Creare una stringa vuota, e controllare che sia vuota.
Creare una stringa che contenga cento ripetizioni di
Python e' bello tra la la.Date le stringhe
"ma biologia","molecolare"e"e' meglio", creare una stringa composta"ma biologia molecolare e' meglio"e poi replicarla mille volte.Controllare se la stringa
"12345"comincia con il carattere 1.Creare una stringa che contenga il solo carattere
\. Controllate conprint, elen()!Controllare che il carattere
xappaia almeno tre volte all’inizio o alla fine di una stringa. Ad esempio, questo e’ vero per:"x....xx" # 1 + 2 >= 3 "xx....x" # 2 + 1 >= 3 "xxxx..." # 4 + 0 >= 3
Ma non per:
"x.....x" # 1 + 1 < 3 "...x..." # 0 + 0 < 3 "......." # 0 + 0 < 3
Data la stringa:
s = "0123456789"
Quali delle seguenti estrazioni sono corrette?
s[9]s[10]s[:10]s[1000]s[0]s[-1]s[1:5]s[-1:-5]s[-5:-1]s[-1000]
Creare una stringa che contenga letteralmente le seguenti due righe di testo, inclusi apici e virgolette:
urlo’: “non farti vedere mai piu’!”
“d’accordo”, rispose il bassotto.
Ci sono almeno due modi per farlo.
Calcolare il valore di 1/7 in Python, ottenendo un
float; mettere il risultato ottenuto nella variabilevalore. Controllare se:- Vi appare la cifra 9.
- I primi sei decimali sono uguali ai secondi sei?
Hint: si puo’ risolvere facilmente l’esercizio convertendo
valoredafloatastr.Date le stringhe:
stringa = "a 1 b 2 c 3" digit = "DIGIT" character = "CHARACTER"
rimpiazzare tutte le cifre con il testo della variabile
digit, e tutti i caratteri alfabetici con quello dicharacter.Opzionalmente, fare tutto in una sola riga di codice.
Data la sequenza primaria della catena A della Tumor Suppressor Protein TP53, riportata qui sotto:
chain_a = """SSSVPSQKTYQGSYGFRLGFLHSGTAKSVTCTYSPALNKM FCQLAKTCPVQLWVDSTPPPGTRVRAMAIYKQSQHMTEVV RRCPHHERCSDSDGLAPPQHLIRVEGNLRVEYLDDRNTFR HSVVVPYEPPEVGSDCTTIHYNYMCNSSCMGGMNRRPILT IITLEDSSGNLLGRNSFEVRVCACPGRDRRTEEENLRKKG EPHHELPPGSTKRALPNNT"""
- Di quante righe e’ composta la sequenza? (Hint: e’ sufficiente contare quanti caratteri di a capo ci sono, e poi …)
- Quanto e’ lunga la sequenza? (Non l’intera stringa: tenete conto dell’esercizio precedente.)
- Rimuovere i caratteri di a capo e mettere il risultato in una nuova
variabile
sequenza. Controllare se le risposte ai punti precedenti sono corrette. - Quante cisteine
"C"ci sono nella sequenza? Quante istidine"H"? - La catena contiene la sotto-sequenza
"NLRVEYLDDRN"? In che posizione? - Come posso usare
find()e l’estrazione[i:j]per estrarre la prima riga della stringachain_a?
Data (una piccola parte) della sequenza terziaria della catena A di TP53:
structure_chain_a = """SER A 96 77.253 20.522 75.007 VAL A 97 76.066 22.304 71.921 PRO A 98 77.731 23.371 68.681 SER A 99 80.136 26.246 68.973 GLN A 100 79.039 29.534 67.364 LYS A 101 81.787 32.022 68.157"""
Ogni riga rappresenta un atomo C_\alpha del backbone della struttura. Di quell’atomo sono riportati, in ordine: il codice del residuo cui appartiene, la catena a cui appartiene (sempre
"A"nel nostro caso), la posizione del residuo nella sequenza primaria, e le coordinate x,y,z del residuo nello spazio tridimensionale.Estrarre la seconda riga usando
find()e l’estrazione[i:j], e metterla in una nuova variabileriga.Estrarre le coordinate del residuo, e metterle in tre variabili
x,y, ez.Ripetere il tutto per la terza riga, e mettere le coordinate in
x_prime, y_prime, z_prime.Calcolare la distanza Euclidea tra i due residui:
d((x,y,z),(x',y',z')) = \sqrt{(x-x')^2 + (y-y')^2 + (z-z')^2}
Hint: per calcolare la distanza e’ necessario usare dei
float.
- Scaricate il file da questo link https://drive.google.com/drive/folders/1MfpXoSSOwrqAGmCQ0cnlZ5P8ERMjc7BG?usp=sharing
Il comando:
dna = open(“data/dna-fasta/fasta.1”).readlines()[2] print(dna)
legge le sequenze di nucleotidi contenute nel file
data/dna-fasta/fasta.1(a patto chepythonsia stato lanciato nella directory giusta) e restituisce una stringa, che noi mettiamo nella variabiledna.- La stringa in
dnae’ vuota? Quanto e’ lunga? Contiene dei caratteri di a capo? (In caso affermativo, rimuoverli.) - I primi tre caratteri sono identici agli ultimi tre?
- I primi tre caratteri sono palindromi rispetto agli ultimi tre?
- Sostituire
AconAde,CconCyt, etc. facendo in modo che i singoli residui siano separati da spazi" ". Mettere il risultato in una nuova variabiledna_espanso.
Soluzioni¶
Note
In alcune soluzioni uso il carattere \ alla fine di una riga di codice.
Usato in questo modo, \ spiega a Python che il comando continua alla
riga successiva. Se non usassi \, Python potrebbe pensare che il
comando finisca li’ e quindi che sia sintatticamente sbagliato – dando
errore.
Potete tranquillamente ignorare questi \.
Soluzioni:
Soluzione:
# 12345 testo = " " print(testo) print(len(testo))
Soluzione:
almeno_uno_spazio = " " in testo # controllo che funzioni print(" " in "nonc'e'alcunospazio") print(" " in "c'e'unsolospazioqui--> <--") print(" " in "ci sono parecchi spazi")
Soluzione:
esattamente_cinque_caratteri = len(testo) == 5 # controllo che funzioni print(len("1234") == 5) print(len("12345") == 5) print(len("123456") == 5)
Soluzione:
stringa_vuota = "" print(len(stringa_vuota) == 0)
Soluzione:
base = "Python e' bello tra la la" ripetizioni = base * 100 # mi assicuro che almeno la lunghezza sia giusta print(len(ripetizioni) == len(base) * 100)
Soluzione:
parte_1 = "ma biologia" parte_2 = "molecolare" parte_3 = "e' meglio" testo = (parte_1 + " " + parte_2 + " " + parte_3) * 1000
Provo cosi’:
comincia_con_1 = "12345".startswith(1)
ma Python mi da’ errore:
Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: startswith first arg must be str or a tuple of str, not int # ^^^^^^^^^^^^^^^^^^^^^ ^^^^^^^
L’errore ci dice (vedi parte evidenziata) che
startswith()richiede che l’argomento sia una stringa, non un intero come nel nostro caso: noi invece le abbiamo passato1, che e’ un intero.La soluzione quindi e’:
comincia_con_1 = "12345".startswith("1") print(comincia_con_1)
che vale
True, come mi aspettavo.Soluzione:
stringa = "\\" stringa print(stringa) print(len(stringa)) # 1
Gia’ controllato nell’esercizio sopra, la risposta e’ no. Verifichiamo comunque:
backslash = "\\" print(backslash*2 in "\\") # False
Primo metodo:
backslash = "\\" condizione = testo.startswith(backslash) or \ testo.endswith(backslash)
Secondo metodo:
condizione = (testo[0] == backslash) or \ (testo[-1] == backslash)
Soluzione:
condizione = \ testo.startswith("xxx") or \ (testo.startswith("xx") and testo.endswith("x")) or \ (testo.startswith("x") and testo.endswith("xx")) or \ testo.endswith("xxx")
Vale la pena di controllare usando gli esempi nell’esercizio.
Soluzione:
s = "0123456789" print(len(s)) # 10
Quali delle seguenti estrazioni sono corrette?
s[9]: corretta, estrae l’ultimo carattere.s[10]: invalida.s[:10]: corretta, estrae tutti i caratteri (ricordate che in secondo indice,10in questo caso, e’ esclusivo.)s[1000]: invalida.s[0]: corretta, estrae il primo carattere.s[-1]: corretta, estrae l’ultimo carattere.s[1:5]: corretta, estrae dal secondo al sesto carattere.s[-1:-5]: corretta, ma non estrae niente (gli indici sono invertiti!)s[-5:-1]: corretta, estrae dal sesto al penultimo carattere.s[-1000]: invalida.
Soluzione (una di due):
testo = """urlo': \"non farti vedere mai piu'!\" \"d'accordo\", rispose il bassotto."""
Soluzione:
valore = 1.0 / 7.0 print(valore) # 0.14285714285714285 valore_come_stringa = str(valore) print(valore_come_stringa) # "0.14285714285714285" print("9" in valore_come_stringa) # False indice_punto = valore_come_stringa.find(".") primi_sei_decimali = valore_come_stringa[indice_punto + 1 : indice_punto + 1 + 6] secondi_sei_decimali = valore_come_stringa[indice_punt + 1 + 6 : indice_punti + 1 + 6 + 6] print(primi_sei_decimali == secondi_sei_decimali) # True
Soluzione:
stringa = "a 1 b 2 c 3" digit = "DIGIT" character = "CHARACTER" risultato = stringa.replace("1", digit) risultato = risultato.replace("2", digit) risultato = risultato.replace("3", digit) risultato = risultato.replace("a", character) risultato = risultato.replace("b", character) risultato = risultato.replace("c", character) print(risultato) # "CHARACTER DIGIT CHARACTER ..."
In una sola riga:
print(stringa.replace("1", digit).replace("2", digit) ...)
Soluzione:
chain_a = """SSSVPSQKTYQGSYGFRLGFLHSGTAKSVTCTYSPALNKM FCQLAKTCPVQLWVDSTPPPGTRVRAMAIYKQSQHMTEVV RRCPHHERCSDSDGLAPPQHLIRVEGNLRVEYLDDRNTFR HSVVVPYEPPEVGSDCTTIHYNYMCNSSCMGGMNRRPILT IITLEDSSGNLLGRNSFEVRVCACPGRDRRTEEENLRKKG EPHHELPPGSTKRALPNNT""" numero_righe = chain_a.count("\n") + 1 print(numero_righe) # 6 # NOTA: qui voglio la lunghezza della *sequenza*, non della *stringa* lunghezza_sequenza = len(chain_a) - chain_a.count("\n") print(lunghezza_sequenza) # 219 sequenza = chain_a.replace("\n", "") print(len(chain_a) - len(sequenza)) # 5 (giusto) print(len(sequenza)) # 219 num_cisteine = sequenza.count("C") num_istidine = sequenza.count("H") print(num_cisteine, num_istidine) # 10, 9 print("NLRVEYLDDRN" in sequenza) # True print(sequenza.find("NLRVEYLDDRN")) # 106 # controllo print(sequenza[106 : 106 + len("NLRVEYLDDRN")]) # "NLRVEYLDDRN" indice_primo_acapo = chain_a.find("\n") prima_riga = chain_a[:indice_primo_acapo] print(prima_riga)
Soluzione:
structure_chain_a = """SER A 96 77.253 20.522 75.007 VAL A 97 76.066 22.304 71.921 PRO A 98 77.731 23.371 68.681 SER A 99 80.136 26.246 68.973 GLN A 100 79.039 29.534 67.364 LYS A 101 81.787 32.022 68.157""" # uso una variabile di nome piu' corto per comodita' chain = structure_chain_a indice_primo_a_capo = chain.find("\n") indice_secondo_a_capo = chain[indice_primo_a_capo + 1:].find("\n") + len(chain[:indice_primo_a_capo + 1]) indice_terzo_a_capo = chain[indice_secondo_a_capo + 1:].find("\n") + len(chain[:indice_secondo_a_capo + 1]) print(indice_primo_a_capo, indice_secondo_a_capo, indice_terzo_a_capo) seconda_riga = chain[indice_primo_a_capo + 1 : indice_secondo_a_capo] print(seconda_riga) # "VAL A 97 76.066 22.304 71.921" # | | | | | | # 01234567890123456789012345678 # 0 1 2 x = seconda_riga[9:15] y = seconda_riga[16:22] z = seconda_riga[23:] print(x, y, z) # NOTA: sono tutte stringhe terza_riga = chain[indice_secondo_a_capo + 1 : indice_terzo_a_capo] print(terza_riga) # "PRO A 98 77.731 23.371 68.681" # | | | | | | # 01234567890123456789012345678 # 0 1 2 x_prime = terza_riga[9:15] y_prime = terza_riga[16:22] z_prime = terza_riga[23:] print(x_prime, y_prime, z_prime) # NOTA: sono tutte stringhe # converto tutte le variabili a float, altrimenti non posso calcolare i # quadrati e la radice quadrata (ne' tantomeno le differenze) x, y, z = float(x), float(y), float(z) x_prime, y_prime, z_prime = float(x_prime), float(y_prime), float(z_prime) diff_x = x - x_prime diff_y = y - y_prime diff_z = z - z_prime distanza = (diff_x**2 + diff_y*82 + diff_z**2)**0.5 print(distanza)
La soluzione si semplifica moltissimo potendo usare
split():righe = chain.split("\n") seconda_riga = righe[1] terza_riga = righe[2] parole = seconda_riga.split() x, y, z = float(parole[-3]), float(parole[-2]), float(parole[-1]) parole = terza_riga.split() x_prime, y_prime, z_prime = float(parole[-3]), float(parole[-2]), float(parole[-1]) distanza = ((x - x_prime)**2 + (y - y_prime)**2 + (z - z_prime)**2)**0.5
Soluzione:
dna = open("data/dna-fasta/fasta.1").readlines()[2] print(len(dna) > 0) # False print(len(dna)) # 61 print("\n" in dna) # True # rimuovo gli 'a capo' dna = dna.strip() print(dna[:3]) # "CAT" print(dna[-3:]) # "CTT" print(dna[:3] == dna[-3:]) # False print((dna[0] == dna[-1] and \ dna[1] == dna[-2] and \ dna[2] == dna[-3])) # False risultato = dna.replace("A", "Ade ") risultato = risultato.replace("C", "Cyt ") risultato = risultato.replace("G", "Gua ") risultato = risultato.replace("T", "Tym ") print(risultato) # "Cyt Ade Tym ..."
Python: Liste¶
Le liste rappresentano sequenze ordinate di oggetti arbitrari.
Warning
Le liste sono mutabili!
Per definire una lista uso le parentesi quadre:
# Una lista di interi (anche ripetuti)
alcuni_interi = [1, 2, 1, 1, 9]
# Una lista di stringhe
proteine_uniprot = ["Y08501", "Q95747"]
# Una lista mista
cose = ["Y08501", 0.13, "Q95747", 0.96]
# Una lista di liste
lista_di_liste = [
["Y08501", 120, 520],
["Q95747", 550, 920],
]
# La lista vuota
una_lista_vuota = []
Warning
Le liste possono contenere elementi ripetuti:
[3, 3, 3, "a", "a", "a"] != [3, "a"]
e l’ordine degli elementi conta:
[1, 2, 3] != [3, 2, 1]
Operazioni¶
| Ritorna | Operatore | Significato |
|---|---|---|
range |
range(int, [int]) |
Restituisce un intervallo di interi |
int |
len(list) |
Restituisce la lunghezza della lista |
list |
list + list |
Concatena le due liste |
list |
list * int |
Replica la lista |
bool |
object in list |
Contolla se un oggetto arbitrario appare nella lista |
list |
list[int:int] |
Estrae una sotto-lista |
list |
list[int] = object |
Sostituisce un elemento della lista |
Esempio. Uso range() per costruire una lista di interi:
>>> intervallo = range(0, 5)
>>> lista = list(intervallo)
>>> print(lista)
[0, 1, 2, 3, 4]
range(5) fa la stessa cosa.
Esempio. La sostituzione di un elemento funziona solo se l’indice corrisponde ad un elemento gia’ esistente:
lista = [0, 1, 2, 3, 4]
lista[0] = "primo"
print(lista) # ["primo", 1, 2, 3, 4]
lista[-1] = "ultimo"
print(lista) # ["primo", 1, 2, 3, "ultimo"]
lista[100] = "oltre l'ultimo" # Errore!
Esercizi¶
Creare una lista vuota. Controllare che sia vuota con
len().Creare una lista con i primi cinque interi non-negativi:
0,1, etc. usandorange().Creare una lista con cento elementi
0.Hint: replicate una lista con un solo elemento.
Date:
lista_1 = list(range(10)) lista_2 = list(range(10, 20))
concatenare le due liste e mettere il risultato in una nuova lista
lista_completa. Quanto vale? E’ uguale al risultato dilist(range(20))?Creare una lista con tre stringhe:
"sono","una","lista". Poi stampare a schermo tipo e lunghezza dei tre elementi, uno per uno.Data:
lista = [0.0, "b", [3], [4, 5]]
Quanto e’ lunga
lista?Di che tipo e’ il primo elemento di
lista?Quanto e’ lungo il secondo elemento di
lista?Quanto e’ lungo il terzo elemento di
lista?Quanto vale l’ultimo elemento di
lista? Quanto e’ lungo?La lista ha un elemento di valore
"b"?La lista ha un elemento di valore
4?Hint: usate
inper controllare.
Che differenza c’e’ tra le seguenti “liste”?:
lista_1 = [1, 2, 3] lista_2 = ["1", "2", "3"] lista_3 = "[1, 2, 3]"
Hint: la terza e’ una lista?
Quali dei seguenti frammenti sono validi/errati?
(Dopo ogni punto, cancellate la lista
listacondel, per evitare problemi con i punti successivi)lista = []lista = [}lista = [[]]lista.append(0)lista = []; lista.append(0)lista = [1 2 3]lista = list(range(3)),elemento = lista[3]lista = list(range(3)),elemento = lista[-1]lista = list(range(3)),sottolista = lista[0:2]lista = list(range(3)),sottolista = lista[0:3]lista = list(range(3)),sottolista = lista[0:-1]lista = list(range(3)),lista[2] = "due"lista = list(range(3)),lista[3] = "tre"lista = list(range(3)),lista[-1] = "tre"lista = list(range(3)),lista[1.2] = "uno virgola due"lista = list(range(3)),lista[1] = ["testo-1", "testo-2"]
Data la lista:
matrice = [ [1, 2, 3], # <-- prima riga [4, 5, 6], # <-- seconda riga [7, 8, 9], # <-- terza riga ] # ^ ^ ^ # | | | # | | +-- terza colonna # | | # | +----- seconda colonna # | # +-------- prima colonna
Come faccio a:
- Estrarre la prima riga?
- Estrarre il secondo elemento della prima riga?
- Sommare gli elementi della prima riga?
- Creare una nuova lista con gli elementi della la seconda colonna?
- Creare una nuova lista con gli elementi la diagonale maggiore?
- Creare una lista concatenando la prima, seconda, e terza riga?
Metodi¶
| Ritorna | Metodo | Significato |
|---|---|---|
None |
list.append(object) |
Aggiunge un elemento alla fine della lista |
None |
list.extend(list) |
Estende una lista con un’altra lista |
None |
list.insert(int,object) |
Inserisce un elemento in una posizione arbitraria |
None |
list.remove(object) |
Rimuove la prima ripetizione di un valore |
None |
list.reverse() |
Inverte la lista |
None |
list.sort() |
Ordina la lista |
int |
list.count(object) |
Conta il numero di ripetizioni di un valore |
Warning
Tutti i metodi delle liste (escluso count()):
- Modificano la lista stessa.
- Restituiscono
None.
Questo comportamento e’ l’esatto opposto di cio’ che accade con i metodi delle stringhe!
Una conseguenza e’ che fare qualcosa come:
print(lista.append(10))
non ha senso, perche’ print stampa il risultato di append(),
che e’ sempre None!
Per lo stesso motivo non possiamo fare:
lista.append(1).append(2).append(3)
perche’ il primo append() restituisce None – che non e’ una
lista, e non possiamo farci append()!
Esempio. append() aggiunge in coda:
lista = list(range(10))
print(lista) # [0, 1, 2, ..., 9]
lista.append(10)
print(lista) # [0, 1, 2, ..., 9, 10]
Notate come lista sia stata modificata! Se invece faccio:
lista = list(range(10))
risultato = lista.append(10)
print(risultato) # None
Come ci aspettavamo, append() restituisce None.
Lo stesso vale per extend():
lista = list(range(10))
risultato = lista.extend(list(range(10, 20)))
print(lista) # [0, 1, 2, ..., 19]
print(risultato) # None
Per inserire elementi in una posizione arbitraria, uso insert():
lista = list(range(10))
risultato = lista.insert(2, "un altro valore")
print(lista) # [0, 1, "un altro valore", 3, ...]
print(risultato) # None
remove() invece prende un valore, non una posizione:
lista = ["una", "lista", "non", "una", "stringa"]
risultato = lista.remove("una")
print(lista) # ["lista", "non", "una", "stringa"]
print(risultato) # None
Anche sort() e reverse() modificano la lista stessa:
lista = [3, 2, 1, 5, 4]
risultato = lista.reverse()
print(lista) # [4, 5, 1, 2, 3]
print(risultato) # None
risultato = lista.sort()
print(lista) # [1, 2, 3, 4, 5]
print(risultato) # None
Invece count() non modifica affatto la lista, e restituisce un int:
lista = ["a", "b", "a", "b", "a"]
risultato_a = lista.count("a") # 3
risultato_b = lista.count("b") # 2
print("ci sono", risultato_a, "a, e", risultato_b, "b")
Esempio. Contrariamente ad append() e soci, la concatenazione non
modifica la lista originale:
lista_1 = list(range(0, 10))
lista_2 = list(range(10, 20))
# usando la concatenazione +
lista_completa = lista_1 + lista_2
print(lista_1, "+", lista_2, "->", lista_completa)
# usando extend()
lista_completa = lista_1.extend(lista_2)
print(lista_1, "estesa con", lista_2, "->", lista_completa)
Nel primo caso tutto funziona come vorrei; nel secondo lista_1 e’ estesa
con lista_2 (che resta invariata), mentre lista_completa vale None.
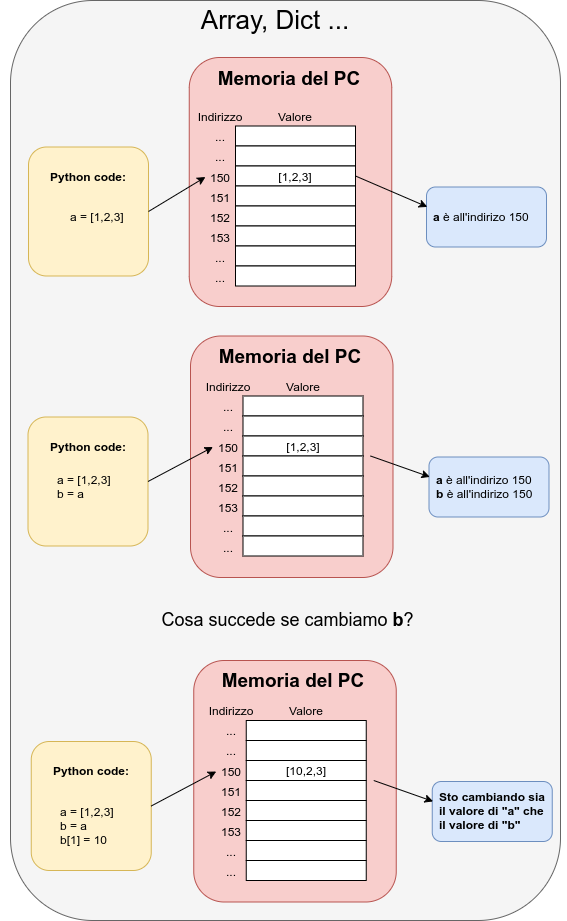
Warning
Le liste sono mutabili, e contengono riferimenti ad oggetti.
Questi due fatti possono dare luogo ad effetti complicati – che esploriamo nei prossimi esercizi.
Esempio. Questo codice:
sottolista = list(range(5))
lista = [sottolista]
print(lista)
crea una lista lista che contiene una lista sottolista come elemento.
Quando modifico sottolista, che e’ una lista e quindi e’ mutabile, finisco
inavvertitamente per modificare anche lista!:
sottolista.append(5)
print(sottolista)
print(lista)
Esempio. Questo codice mostra un’altra anomalia:
lista = list(range(5))
print(lista)
finta_copia = lista # copio solo il *riferimento* a lista!
print(finta_copia)
lista.append(5)
print(lista)
print(finta_copia) # Ooops!
Questo accade perche’ lista_1 e lista_2 si riferiscono allo stesso
oggetto lista. Se voglio creare una copia reale della lista lista,
scrivo:
lista = list(range(5))
print(lista)
copia_vera = list(lista)
# oppure
# copia_vera = [elem for elem in lista]
print(copia_vera)
lista.append(5)
print(lista)
print(copia_vera)
Esercizi¶
Inserire nella lista
listaprima un intero, poi una stringa, poi una lista.Warning
La lista deve esistere gia’ prima di poterci fare
append(),extend(),insert(), etc.. Ad esempio:>>> una_lista_che_non_ho_mai_definito.append(0)
da’ errore:
Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'una_lista_che_non_ho_mai_definito' is not defined
Partendo (per ogni punto) da:
lista = list(range(3))
cosa fanno i seguenti frammenti di codice? (Ripartite ogni volta da
lista = list(range(3)).)lista.append(3)lista.append([3])lista.extend([3])lista.extend(3)lista.insert(0, 3)lista.insert(3, 3)lista.insert(3, [3])lista.insert([3], 3)
Che differenza c’e’ tra:
lista = [] lista.append(list(range(10))) lista.append(list(range(10, 20)))
e:
lista = [] lista.extend(list(range(10))) lista.extend(list(range(10, 20)))
Di che lunghezza e’
listanei due casi?Che cosa fa questo codice?:
lista = [0, 0, 0, 0] lista.remove(0)
Che cosa fa questo codice?:
lista = [1, 2, 3, 4, 5] lista.reverse() lista.sort()
Posso riscriverlo cosi’?:
lista = [1, 2, 3, 4, 5] lista.reverse().sort()
Data la lista:
lista = list(range(10))
mettere in
lista_inversagli elementi dilistain ordine inverso (dall’ultimo al primo) usandoreverse().listanon deve essere alterata.Data la lista:
frammenti = [ "KSYK", "SVALVV", "GVTGI", "VGSSLAEVLKLPD", ]
mettere in
frammenti_ordinatigli elementi diframmentiordinati alfanumericamente consort().frammentinon deve essere alterata.(Una Curiosita’ Inutile). Che “struttura” ha questa lista?:
lista = [] lista.append(lista)
Metodi Stringhe-Liste¶
| Ritorna | Metodo | Significato |
|---|---|---|
list-of-str |
str.split(str) |
Rompe una stringa in una lista di stringhe |
str |
str.join(list-of-str) |
Ricompone una lista di stringhe in una stringa |
Esempio. La lista di stringhe:
tabella = [
"nome,cognome,numero di premi nobel vinti",
"Albert,Einstein,1",
"Marie,Curie,2",
]
che riporta informazioni su personaggi noti in tre colonne separate da
virgole ",".
Estraggo i titoli delle colonne dall’intestazione (la prima riga della
tabella) con split():
titoli_colonne = tabella[0].split(",")
print(titoli_colonne)
print(type(titoli_colonne))
e calcolo quante colonne ci sono:
num_colonne = len(titoli_colonne)
Esempio. join() e’ utile per ricomporre liste di stringhe, ad
esempio:
lista_di_stringhe = ["uno", "due", "tre"] * 100
print(type(lista_di_stringhe), lista_di_stringhe)
stringa_intera = " ".join(lista_di_stringhe)
print(type(stringa_intera), stringa_intera)
Warning
Quando uso join(), la lista deve contenere stringhe! Questo
non funziona:
" ".join([1, 2, 3])
Esercizi¶
Data la stringa:
testo = """The Wellcome Trust Sanger Institute is a world leader in genome research."""
mettere le parole di
testoin una lista di stringhe. Poi stampare a schermo quante parole contiene.Poi mettere in
prima_rigala prima riga ditesto.Fare la stessa cosa con
seconda_riga.Estrarre la prima parola di
seconda_rigae stamparla a schermo.La tabella di stringhe:
tabella = [ "protein | database | domain | start | end", "YNL275W | Pfam | PF00955 | 236 | 498", "YHR065C | SMART | SM00490 | 335 | 416", "YKL053C-A | Pfam | PF05254 | 5 | 72", "YOR349W | PANTHER | 353 | 414", ]
presa da Saccharomyces Genome Database, rappresenta una lista di (informazioni su) domini identificati nella sequenza di alcune proteine del lievito.
Ogni riga e’ un dominio, tranne la prima (che fa da intestazione).
Usando
split()ottenere una lista dei titoli delle varie colonne, avendo cura di accertarsi che le stringhe che corrispondono ai titoli non contengano spazi superflui.Hint: non e’ necessario usare
strip().Data la lista di stringhe:
parole = ["parola_1", "parola_2", "parola_3"]
costruire, usando solo
join()ed un opportuno delimitatore le seguenti stringhe:"parola_1 parola_2 parola_3""parola_1,parola_2,parola_3""parola_1 e parola_2 e parola_3""parola_1parola_2parola3"r"parola_1\parola_2\parola_3"
Data la lista di stringhe:
versi = [ "Taci. Su le soglie", "del bosco non odo", "parole che dici", "umane; ma odo", "parole piu' nuove", "che parlano gocciole e foglie", "lontane." ]
usare
join()per creare una stringa multi-linea con i versi inversi.Il risultato ("poesia") deve essere:>>> print(poesia) Taci. Su le soglie del bosco non odo parole che dici umane; ma odo parole piu' nuove che parlano gocciole e foglie lontane.
Hint: che delimitatore devo usare?
List Comprehension¶
La list comprehension permette di trasformare e/o filtrare una lista.
Data una lista qualunque lista_originale, posso creare una nuova lista
che contiene solo gli elementi che soddisfano una certa condizione:
lista_filtrata = [elemento
for elemento in lista_originale
if condizione(elemento)]
Qui condizione() ce la inventiamo noi.
Esempio. Creo una nuova lista contenente solo i numeri pari da 0 a 9:
numeri = range(10)
numeri_pari = [numero for numero in numeri
if numero % 2 == 0]
print(numeri_pari)
Esempio. Data la lista di sequenze nucleotidiche:
sequenze = ["ACTGG", "CCTGT", "ATTTA", "TATAGC"]
tengo solo le sequenze che contengono almeno una adenosina:
sequenze_con_a = [sequenza for sequenza in sequenze
if "A" in sequenza]
print(sequenze_con_a)
Per tenere solo quelle che non contengono adenosina, nego la condizione:
sequenze_senza_a = [sequenza for sequenza in sequenze
if not "A" in sequenza]
print(sequenze_senza_a)
Esempio. Se ometto la condizione, cosi’:
lista_2 = [elemento for elemento in lista]
ottengo una copia di lista.
Esempio. Uso una lista di liste per descrivere una rete di regolazione tra geni:
microarray = [
["G1C2W9", "G1C2Q7", 0.2],
["G1C2W9", "G1C2Q4", 0.9],
["Q6NMS1", "G1C2W9", 0.8],
# ^^^^^^ ^^^^^^ ^^^
# gene1 gene2 correlazione
]
Ogni lista “interna” ha tre elementi: i primi due sono identificativi di geni di A. Thaliana, il terzo e’ una misura di correlazione tra l’espressione dei due geni in un qualche microarray.
Posso usare una list comprehension per tenere solo le coppie di geni con correlazione alta:
geni_altamente_correlati = \
[tripla[:-1] for tripla in microarray if tripla[-1] > 0.75]
oppure ottenere i geni che sono altamente coespressi con il gene "G1C2W9":
soglia = 0.75
geni_coespressi = \
[tripla[0] for tripla in microarray
if tripla[1] == "G1C2W9" and tripla[-1] >= soglia] + \
[tripla[1] for tripla in microarray
if tripla[0] == "G1C2W9" and tripla[-1] >= soglia]
Warning
Il nome della variabile che itera sugli elementi (nell’esempio sopra,
elemento) e’ arbitrario. Questo codice:
intervallo = range(10)
print([x for x in intervallo if x > 5])
e’ identico a questo:
intervallo = range(10)
print([y for y in intervallo if y > 5])
Il nome della variabile, x o y, e’ immateriale.
La list comprehension puo’ essere usata anche per creare una nuova lista
che contiene gli elementi di lista_originale trasformati (uno per uno,
individualmente) in qualche modo:
lista_trasformata = [trasforma(elemento)
for elemento in lista_originale]
Qui trasforma() e’ una “trasformazione” che ci inventiamo noi.
Esempio. Dato l’intervallo:
numeri = range(10)
creo una nuova lista con i loro doppi:
doppi = [numero * 2 for numero in numeri]
# ^^^^^^^^^^
# trasformazione
print(doppi)
Esempio. Data la lista di percorsi relativi alla directory data/:
percorsi = ["aatable", "fasta.1", "fasta.2"]
prefisso il percorso "data/" a ciascun elemento:
percorsi_completi = ["data/" + percorso
for percorso in percorsi]
print(percorsi_completi)
Esempio. Data la lista di sequenze primarie:
sequenze = [
"MVLTIYPDELVQIVSDKIASNK",
"GKITLNQLWDIS",
"KYFDLSDKKVKQFVLSCVILKKDIE",
"VYCDGAITTKNVTDIIGDANHSYS",
]
metto in una lista nuova lunghezze le lunghezze di ciascuna sequenza,
in ordine:
lunghezze = [len(sequenza) for sequenza in sequenze]
print(lunghezze)
Esempio. Data una lista di stringhe:
atomi = [
"SER A 96 77.253 20.522 75.007",
"VAL A 97 76.066 22.304 71.921",
"PRO A 98 77.731 23.371 68.681",
"SER A 99 80.136 26.246 68.973",
"GLN A 100 79.039 29.534 67.364",
"LYS A 101 81.787 32.022 68.157",
]
che rappresenta (parte della) struttura terziaria di una catena proteica,
voglio ottenere una lista di liste che contiene, per ogni residuo (stringa)
in atomi, le sue coordinate (tre elementi).
Scrivo:
coordinate = [riga.split()[-3:] for riga in atomi]
ed ottengo:
>>> print(coordinate)
[
["77.253", "20.522", "75.007"],
["76.066", "22.304", "71.921"],
["77.731", "23.371", "68.681"],
["80.136", "26.246", "68.973"],
["79.039", "29.534", "67.364"],
["81.787", "32.022", "68.157"],
]
Come funziona questo codice? Consideriamo la prima riga di``atomi``:
"SER A 96 77.253 20.522 75.007"
Quando la list comprehension incontra questa riga, fa questo:
riga = "SER A 96 77.253 20.522 75.007"
poi applica la trasformazione riga.split()[-3:], i cui passaggi sono:
>>> print(riga.split())
["SER", "A", "96", "77.253", "20.522", "75.007"]
# ^^^^^^^^ ^^^^^^^^ ^^^^^^^^
# -3 -2 -1
>>> print(riga.split()[-3:])
["77.253", "20.522", "75.007"]
quindi il risultato della trasformazione applicata a questa riga e’ la lista:
["77.253", "20.522", "75.007"]
Questa lista viene appesa a coordinate.
A questo punto la list comprehension prende la seconda seconda riga di atomi:
"VAL A 97 76.066 22.304 71.921"
la mette in riga, ed applica la stessa trasformazione, ottenendo la lista:
["76.066", "22.304", "71.921"]
che appende a coordinate.
Poi prende la terza riga di atomi, etc.
Infine, posso combinare filtro e trasformazione per creare una nuova lista che
contiene solo gli elementi di lista_originale che soddisfano una certa
condizione, ma trasformati in qualche modo:
nuova_lista = [trasforma(elemento)
for elemento in lista_originale
if condizione(elemento)]
Esempio. Dati gli interi da 0 a 10, voglio tenere solo quelli pari e dividerli per 3:
pari_diviso_3 = [float(numero) / 3
for numero in range(10)
if numero % 2 == 0]
Notate che la condizione opera su numero (l’elemento originale della lista
oridinale, non trasformato), non su float(numero) / 3.
Warning
La list comprehension costruisce una nuova lista, lasciando l’originale inalterata, sia quando filtro:
numeri = range(10)
numeri_pari = [numero
for numero in lista_originale
if numero % 2 == 0]
print(numeri, "e' lunga", len(numeri))
print(numeri_pari, "e' lunga", len(numeri_pari))
sia quando trasformo:
numeri = range(10)
doppi = [numero * 2 for numero in numeri]
print(numeri)
print(doppi)
Esercizi¶
Warning
Nei prossimi esercizi, se open() da’ errore e’ probabile che non
abbiate fatto partire il terminale dalla directory giusta. Ad esempio
in questo caso:
>>> righe = open("file/che/non/esiste").readlines()
Python da’ (giustamente) errore:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IOError: [Errno 2] No such file or directory: 'file/che/non/esiste'
# ^^^^^^^^^^^^^^^^^^^^^^^^^ ^^^^^^^^^^^^^^^^^^^^^
# non esiste questo file! nome del file
Assicuratevi di adattare il percorso in base alla directory nella quale vi trovate.
Data la lista:
lista = list(range(100))
Creare una nuova lista
lista_piu_3contenente il valore degli elementi dilistapiu’3. Il risultato deve essere:[3, 4, 5, ...]
Creare una nuova lista
lista_disparicontenente solo gli elementi dispari dilista. Il risultato deve essere:[1, 3, 5, ...]
Hint: un intero e’ dispari se e solo se il risultato di:
numero % 2e’
1.Creare una nuova lista
lista_opposticontenente l’opposto aritmetico (l’opposto di x e’ -x) degli elementi dilista. Il risultato deve essere:[0, -1, -2, ...]
Creare una nuova lista
lista_inversicontenente l’inverso aritmetico (l’inverso aritmetico di x e’ \frac{1}{x}) degli elementi dilista. Se l’inverso di un elemento non esiste, l’elemento deve essere ignorato (non comparire inlista_inversi). Il risultato deve essere:[1, 0.5, 0.33334, ...]
Hint: l’unico intero senza un inverso e’ 0.
Creare una nuova lista contenente solo il primo e l’ultimo elemento di
lista. Il risultato deve essere:[0, 99]
Hint: si fa con una list comprehension?
Creare una nuova lista contenente tutti gli elementi di
listatranne il primo e l’ultimo. Il risultato deve essere:[1, 2, ..., 97, 98]
Contare quanti numeri dispari ci sono in
lista. Il risultato deve essere50.Hint: basta usare una list comprehension?
Creare una nuova lista contenente tutti gli elementi di
listadivisi per 5 (anche quelli non divisibili per 5!). Il risultato deve essere:[0.0, 0.2, 0.4, ...]
Creare una nuova lista
lista_multipli_5_divisicontenente solo i multipli di 5, ma divisi per 5. Il risultato deve essere:[0.0, 1.0, 2.0, ..., 19.0]
Creare una nuova lista
lista_di_stringhecontenente tutti gli elementi dilistama convertiti in stringhe. Il risultato deve essere:["0", "1", "2", ...]
Contare quante stringhe rappresentanti un numero dispari ci sono in
lista_di_stringhe.Creare una stringa che contenga tutti gli elementi di
lista, visti come stringhe, e separati da uno spazio. Il risultato deve essere:"0 1 2 ..."Hint: basta usare una list comprehension?
Per ciascuno dei punti seguenti, scrivere due list comprehension che producano
lista_1dalista_2e viceversa.lista_1 = [1, 2, 3] lista_2 = ["1", "2", "3"]
lista_1 = ["nome", "cognome", "eta'"] lista_2 = [["nome"], ["cognome"], ["eta'"]]
lista_1 = ["ACTC", "TTTGGG", "CT"] lista_2 = [["actc", 4], ["tttgggcc", 6], ["ct", 2]]
Data la lista:
lista = list(range(10))
quali dei seguenti frammenti sono validi o errati, e cosa fanno?
[x for x in lista][y for y in lista][y for x in lista]["x" for x in lista][str(x) for x in lista][x for str(x) in lista][x + 1 for x in lista][x + 1 for x in lista if x == 2]
Data la lista di stringhe
dnarestituita da:dna = open("data/dna-fasta/fasta.1").readlines() print(dna)
- Creare una nuova lista di stringhe che contenga tutte le stringhe in
dnatranne quella di intestazione (la riga che comincia per">"). - Ci sono caratteri di a capo o spazi nella lista di stringhe ottenuta? Se si’, creare una nuova lista di stringhe che sia identica a quella ottenuta, ma dove le stringhe non contengano caratteri di a capo ne’ spazi.
- Concatenare in una singola stringa tutte le righe ottenute.
- Calcolare la percentuale di citosina e guanina nella sequenza ottenuta.
- Calcolare il GC-content della sequenza.
- Creare una nuova lista di stringhe che contenga tutte le stringhe in
Consideriamo la stringa:
risultato_cdhit = """\ >Cluster 0 0 >YLR106C at 100.00% >Cluster 50 0 >YPL082C at 100.00% >Cluster 54 0 >YHL009W-A at 90.80% 1 >YHL009W-B at 100.00% 2 >YJL113W at 98.77% 3 >YJL114W at 97.35% >Cluster 52 0 >YBR208C at 100.00% """
ottenuta raggruppando le strutture primarie del genoma di S. Cerevisiae (preso da SGD) con un software di clustering (CD-HIT).
risultato_cdhitcodifica in forma testuale alcuni cluster di proteine raggruppate in base alla similarita’ delle loro sequenze.Un gruppo comincia con la riga:
>Cluster N
dove
Ne’ il numero del cluster. I contenuti del cluster sono dati dalle righe successive, ad esempio:>Cluster 54 0 >YHL009W-A at 90.80% 1 >YHL009W-B at 100.00% 2 >YJL113W at 98.77% 3 >YJL114W at 97.35%
rappresenta un gruppo di quattro sequenze, denominato
"Cluster 54": di quel gruppo fanno parte la proteina"YHL009W-A"con una similarita’ del90.80%, la proteina"YHL009-B"con una similarita’ del100.00%, etc.Data
risultato_cdhit, usare delle list comprehension per:Estrarre i nomi dei vari cluster. Il risultato deve essere:
>>> print(nomi_cluster) ["0", "50", "54", "52"]
Estrarre i nomi di tutte le proteine (non importa se ci sono doppioni). Il risultato deve essere:
>>> print(proteine) ["YLR1106C", "YPL082C", "YHL00W-A", ...]
Estrarre le coppie proteina-percentuale per tutte le proteine. il risultato deve essere:
>>> print(coppie_proteina_percentuale) [["YLR106C", 100.0], ["YPL082C", 100.0], ["YHL009W-A", 90.8], # ... ]
Il comando:
righe = open("data/prot-pdb/1A3A.pdb").readlines() print(" ".join(righe)) # stampo le righe print(len(righe)) # 5472
restituisce una lista di righe del file
data/prot-pdb/1A3A.pdb, preso dalla Protein Data Bank. Descrive una proteina di E. Coli.Hint: aprite il file con un editor di testo (
nano,gedit, quello che preferite) e fatevi un’idea dei contenuti prima di procedere!Estrarre tutte le righe che cominciano per
"SEQRES"e mettere il risultato nella listarighe_seqres.Dovrebbero esserci esattamente
48righe di questo tipo. Il risultato deve somigliare a questo:>>> print(" ".join(righe_seqres)) SEQRES 1 A 148 MET ALA ASN LEU PHE LYS LEU GLY ALA GLU ASN ILE PHE SEQRES 2 A 148 LEU GLY ARG LYS ALA ALA THR LYS GLU GLU ALA ILE ARG SEQRES 3 A 148 PHE ALA GLY GLU GLN LEU VAL LYS GLY GLY TYR VAL GLU # ... SEQRES 10 D 148 LEU THR ASN ALA LEU ASP ASP GLU SER VAL ILE GLU ARG SEQRES 11 D 148 LEU ALA HIS THR THR SER VAL ASP GLU VAL LEU GLU LEU SEQRES 12 D 148 LEU ALA GLY ARG LYS # ^ ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ # catena sequenza primaria della catena
La prima colonna delle righe in
righe_seqrese’ sempre"SEQRES"(per costruzione), la terza e’ il nome della catena di 1A3A descritta in quella riga, mentre le colonne dalla quinta in poi descrivono la sequenza primaria della catena stessa.Estrarre le catene da
righe_seqres(non importa se ci sono doppioni).Il risultato deve essere:
>>> print(catene) ["A", ..., "B", ..., "C", ..., "D", ...]
Estrarre solo le righe della catena B e metterle in
righe_seqres_B. Devono esserci esattamente12righe.Estrarre da
righe_seqres_Bla sequenza della catena B e metterla in una sola stringasequenza_B.Il risultato deve essere:
>>> print(sequenza_B) "MET ALA ASN LEU PHE ... ALA GLY ARG LYS"
Estrarre da
righetutte le righe che cominciano per"HELIX"e mettere il risultato nella listarighe_helix.Devono esserci esattamente
30righe di questo tipo. Il risultato deve somigliare a questo:>>> print(" ".join(righe_helix)) HELIX 1 1 ALA A 9 ASN A 11 5 3 HELIX 2 2 LYS A 21 LYS A 34 1 14 HELIX 3 3 PRO A 40 LEU A 52 5 13 HELIX 4 4 VAL A 68 ARG A 73 5 6 HELIX 5 5 HIS A 111 ALA A 121 1 11 # ^^^^^^^^^^ ^^^^^^^^^^ # inizio elica fine elica
La prima colonna delle righe in
righe_helixe’ sempre"HELIX"(per costruzione). Ogni riga descrive una \alpha-helix della proteina 1A3A.La quarta, quinta e sesta colonna descrivono il residuo dal quale parte l’elica: tipo del residuo, catena di riferimento, e posizione del residuo.
La settima, ottava e nona colonna descrivono il residuo dove finisce l’elica: sempre con tipo, catena e posizione.
Estrarre una lista
info_elichein cui ogni elemento rappresenta un’elica, e ne contiene la posizione di inizio, la posizione di fine, e la lunghezza.
Data la matrice 3\times 3:
matrice = [list(range(0,3)), list(range(3,6)), list(range(6,9))]
- Mettere in una lista
prima_rigala prima riga. - Mettere in una lista
prima_colonnala prima colonna. - Creare una matrice
sottosoprache contenga le righe dimatricema sottosopra. - (Difficile.) Creare una matrice
palindromoche contenga le righe dimatricema da destra a sinistra. - (Difficile.) Ricreare
matricecon una sola list comprehension.
- Mettere in una lista
(Difficile). Data la lista:
lista = range(100)
Creare una lista
lista_quadraticontenente i quadrati degli elementi dilista. Il risultato deve essere:[0, 1, 4, 9, ...]
Poi creare una lista
lista_differenze_quadratiche contenga, nella posizionei-esima il valore:lista_quadrati[i+1] - lista_quadrati[i]
per tutti, tranne l’ultimo, valore di
lista_quadrati. E’ consigliabile usare piu’ di un passaggio, ed eventualmente liste ausiliarie.(Che numeri avete ottenuto? Ecco perche’.)
Python: Liste (Soluzioni)¶
Note
In alcune soluzioni uso il carattere \ alla fine di una riga di codice.
Usato in questo modo, \ spiega a Python che il comando continua alla
riga successiva. Se non usassi \, Python potrebbe pensare che il
comando finisca li’ e quindi che sia sintatticamente sbagliato – dando
errore.
Potete tranquillamente ignorare questi \.
Soluzioni Operazioni¶
Soluzione:
lista = [] print(lista, len(lista)) # controllo
Soluzione:
lista = list(range(5)) print(lista, len(lista)) # controllo print(len(lista))
Soluzione:
lista = [0] * 100 print(lista, len(lista)) # controllo
Soluzione:
lista_1 = list(range(10)) lista_2 = list(range(10, 20)) lista_completa = lista_1 + lista_2 print(lista_completa) print(lista_completa) == list(range(20)) # Ture
Soluzione:
lista = ["sono", "una", "lista"] print(lista, len(lista)) # controllo print(len(lista[0])) print(len(lista[1])) print(len(lista[2]))
Soluzione:
lista = [0.0, "b", [3], [4, 5]] print(len(lista)) # 4 print(type(lista[0])) # float print(lista[1], len(lista[1])) # "b", 1 print(lista[2], len(lista[2])) # [3], 1 print(lista[-1], len(lista[-1])) # [4, 5], 2 print("b" in lista) # True print(4 in lista) # False print(4 in lista[-1]) # True
Soluzione: la prima e’ una lista di interi, la seconda una lista di stringhe, mentre la terza e’ una stringa!:
print(type(lista_1)) # list print(type(lista_2)) # list print(type(lista_3)) # str
Soluzioni:
# una lista vuota lista = [] print(len(lista)) # 0 del lista # sintassi non valida, Python da' errore lista = [} # una lista che contiene una lista vuota lista = [[]] print(len(lista)) # 1 print(len(lista[0])) # 0 del lista # non funziona perche' lista non e' definita! lista.append(0) # questa invece funziona lista = [] lista.append(0) print(lista) # [0] del lista # non funziona perche' mancano le virgole! lista = [1 2 3] # da' errore perche' la lista ha solo 3 elementi! lista = list(range(3)) print(lista[3]) # estrae l'ultimo elemento lista = list(range(3)) print(lista[-1]) del lista # estrae i primi due elementi (lista[2], il terzo, # e' escluso) lista = list(range(3)) sottolista = lista[0:2] print(lista) del lista # estrare tutti gli elementi (lista[3], che 'non # esiste', e' escluso) lista = list(range(3)) sottolista = lista[0:3] print(lista) del lista # estrae i primi due elementi (lista[-1], il terzo, # e' escluso) lista = list(range(3)) sottolista = lista[0:-1] print(lista) del lista # inserisce in terza posizione la stringa "due" lista = list(range(3)) lista[2] = "due" print(lista) del lista # non funziona: la lista contiene solo tre elementi, # quindi non ha una quarta posizione, e Python da' # errore lista = list(range(3)) lista[3] = "tre" # inserisce in terza posizione la stringa "tre" lista = list(range(3)) lista[-1] = "tre" print(lista) del lista # l'indice deve essere un intero, Python da' errore lista = list(range(3)) lista[1.2] = "uno virgola due" # sostituisce il secondo elemento di lista (cioe' 1) # con una lista di due stringhe; e' perfettamente # legale: le liste *possono* contenere altre stringhe lista = list(range(3)) lista[1] = ["testo-1", "testo-2"] print(lista) del lista
Soluzione:
matrice = [ [1, 2, 3], [4, 5, 6], [7, 8, 9], ] prima_riga = matrice[0] print(prima_riga) secondo_elemento_prima_riga = prima_riga[1] # oppure secondo_elemento_prima_riga = matrice[0][1] print(secondo_elemento_prima_riga) somma_prima_riga = matrice[0][0] + matrice[0][1] + matrice[0][2] print(somma_prima_riga) seconda_colonna = [matrice[0][1], matrice[1][1], matrice[2][1]] print(seconda_colonna) diagonale = [matrice[0][0], matrice[1][1], matrice[2][2]] print(diagonale) tre_righe_assieme = matrice[0] + matrice[1] + matrice[2] print(tre_righe_assieme)
Soluzioni Metodi¶
Prima dichiaro una lista qualunque, ad esempio quella vuota:
lista = []
poi aggiungo i vari elementi richiesti con
append():lista.append(0) lista.append("testo") lista.append([0, 1, 2, 3])
Soluzione:
# aggiunge un 3 alla fine della lista lista = list(range(3)) lista.append(3) print(lista) del lista # aggiunge una lista con un 3 dentro alla fine della lista lista = list(range(3)) lista.append([3]) print(lista) del lista # aggiunge un 3 (il solo elemento contenuto nella lista [3]) alla # fine della lista lista = list(range(3)) lista.extend([3]) print(lista) del lista # non funziona: extend() estende una lista con i contenuti # di un'altra lista, ma qui 3 *non* e' una lista! Python da' # errore lista = list(range(3)) lista.extend(3) # sostituisce l'elemento in posizione 0, il primo, con il # valore 3 lista = list(range(3)) lista.insert(0, 3) print(lista) del lista # inserisce un 3 alla fine di lista lista = list(range(3)) lista.insert(3, 3) print(lista) del lista # inserisce la lista [3] alla fine di lista lista = list(range(3)) lista.insert(3, [3]) print(lista) del lista # non funziona: il primo argomento di insert() deve essere # un intero, qui gli stiamo dando una lista! Python da' errore lista = list(range(3)) lista.insert([3], 3)
Soluzione:
lista = [] lista.append(range(10)) lista.append(range(10, 20)) print(lista)
Qui uso
append(), che inserisce un elemento alla fine dilista. In questo caso inserisco due liste, cioe’ i risultati dirange(10)erange(10, 20).E’ chiaro che
len(lista)e’2, visto che ho inserito solo due elementi.Invece:
lista = [] lista.extend(range(10)) lista.extend(range(10, 20)) print(lista)
fa uso di
extend(), che “estende” una lista con un’altra lista. Qui la lista finale ha20elementi, come si evince con:print(len(lista))
Soluzione:
lista = [0, 0, 0, 0] lista.remove(0) print(lista)
solo la prima ripetizione di
0viene rimossa!Soluzione:
lista = [1, 2, 3, 4, 5] # inverte l'ordine degli elementi di lista lista.reverse() print(lista) # ordina gli elementi di lista lista.sort() print(lista)
Il risultato e’ che dopo le due operazioni
listatorna al suo valore iniziale.Invece questo:
lista = [1, 2, 3, 4, 5] lista.reverse().sort()
non si puo’ fare. Il risultato di
lista.reverse()e’None:lista = [1, 2, 3, 4, 5] risultato = lista.reverse() print(risultato)
che certamente non e’ una lista, e quindi non ci posso fare sopra
sort(). Python dara’ errore.Sono tentato di scrivere:
lista = list(range(10)) lista_inversa = lista.reverse() print(lista) # modificata! print(lista_inversa) # None!
ma questa cosa non funziona:
reverse()modificalistae restituisceNone! Perdipiu’ questo codice modificalistadirettamente, ed io non voglio.Quindi prima faccio una copia di
lista, e poi ordino quella:lista = list(range(10)) lista_inversa = lista[:] # *non* lista_inversa = lista lista_inversa.reverse() print(lista) # invariata print(lista_inversa) # invertita
Invece questo codice:
lista = list(range(10)) lista_inversa = lista lista_inversa.reverse() print(lista) # modificata! print(lista_inversa) # invertita
non funziona come vorrei: quello che succede e’ che
lista_inversacontiene non una copia dilista, ma un riferimento allo stesso oggetto riferito dalista.Quindi quando inverto
lista_inversafinisco per invertire anchelista.Come sopra:
frammenti = [ "KSYK", "SVALVV" "GVTGI", "VGSSLAEVLKLPD", ] frammenti_ordinati = frammenti.sort()
non funziona:
sort()ordinalistae restituisceNone! Quindi sono costretto a fare prima una copia diframmenti, e poi ad ordinare quella:frammenti_ordinati = frammenti[:] frammenti_ordinati.sort() print(frammenti) # invariata print(frammenti_ordinati) # ordinata
Soluzione:
lista = [] lista.append(lista) print(lista)
crea una lista che contiene se’ stessa;
listae’ una struttura che in gergo viene detta ricorsiva.listae’ chiaramente infinita (in termini di annidamento), visto che posso farci cose come queste:print(lista) print(lista[0]) print(lista[0][0]) print(lista[0][0][0]) print(lista[0][0][0][0]) # ...
Visto che
listaha profondita’ infinita, Python quando la stampa usa un’ellissi...per indicare che c’e’ una quantita’ infinita di liste dentro alista(ed ovviamente non puo’ stamparle tutte).Non vedremo altre strutture ricorsive nel corso.
Soluzioni Metodi Stringhe-Liste¶
Soluzione:
testo = """The Wellcome Trust Sanger Institute is a world leader in genome research."""" parole = testo.split() print(len(parole)) righe = testo.split("\n") prima_riga = righe[0] print("la prima riga e':", prima_riga) seconda_riga = righe[1] print("la seconda riga e':", seconda_riga) print("la prima parola della seconda riga e':", seconda_riga.split()[0])Soluzione:
tabella = [ "protein | database | domain | start | end", "YNL275W | Pfam | PF00955 | 236 | 498", "YHR065C | SMART | SM00490 | 335 | 416", "YKL053C-A | Pfam | PF05254 | 5 | 72", "YOR349W | PANTHER | 353 | 414", ] prima_riga = tabella[0] titoli_colonne_quasi = prima_riga.split("|") print(titoli_colonne_quasi) # ["protein ", " database ", ...] # purtroppo qui i titoli delle colonne contengono spazi superflui # per evitarli posso cambiare il delimitatore che do a split() titoli_colonne = prima_riga.split(" | ") print(titoli_colonne) # ["protein", "database", ...]
Volendo si puo’ usare anche
strip()assieme ad una list comprehension sutitoli_colonne_quasi, ma (come appena dimostrato) non e’ necessario.Soluzione:
parole = ["parola_1", "parola_2", "parola_3"] print(" ".join(parole)) print(",".join(parole)) print(" e ".join(parole)) print("".join(parole)) backslash = "\\" print(backslash.join(parole))
Soluzione:
versi = [ "Taci. Su le soglie" "del bosco non odo" "parole che dici" "umane; ma odo" "parole piu' nuove" "che parlano gocciole e foglie" "lontane." ] poesia = "\n".join(versi)
Soluzioni List Comprehension¶
Soluzioni:
Soluzione:
lista_piu_tre = [numero + 3 for numero in lista] print(lista_piu_tre) # controllo
Soluzione:
lista_dispari = [numero for numero in lista if (numero % 2 == 1)]
Soluzione:
lista_opposti = [-numero for numero in lista]
Soluzione:
lista_inversi = [1.0 / numero for numero in lista if numero != 0]
Soluzione:
primo_e_ultimo = [lista[0], lista[-1]]
Soluzione:
dal_secondo_al_penultimo = lista[1:-1]
Soluzione:
lista_dispari = [numero for numero in lista if (numero % 2 == 1)] quanti_dispari = len(lista_dispari) print(quanti_dispari)
oppure abbreviando:
quanti_dispari = len([numero for numero in lista if (numero % 2 == 1)])
Soluzione:
lista_divisi_per_5 = [float(numero) / 5 for numero in lista]
Soluzione:
lista_multipli_5_divisi = [float(numero) / 5.0) for numero in lista if (numero % 5 == 0)]
Soluzione:
lista_di_stringhe = [str(numero) for numero in lista]
Soluzione:
# Come sopra, ma iterando su `lista_di_stringhe` # piuttosto che direttamente su `lista` quanti_dispari = len([stringa for stringa in lista_di_stringhe if (int(stringa) % 5 == 0)])
Soluzione:
testo = " ".join([str(numero) for numero in lista])
Occhio che se dimentico di fare
str(numero),join()si rifiuta di funzionare.
Soluzioni:
# andata lista_1 = [1, 2, 3] lista_2 = [str(x) for x in lista_1] # ritorno lista_2 = ["1", "2", "3"] lista_1 = [int(x) for x in lista_2]
# andata lista_1 = ["nome", "cognome", "eta'"] lista_2 = [[x] for x in lista_1] # ritorno lista_2 = [["nome"], ["cognome"], ["eta'"]] lista_1 = [l[0] for l in lista_2]
# andata lista_1 = ["ACTC", "TTTGGG", "CT"] lista_2 = [[x.lower(), len(x)] for x in lista_1] # ritorno lista_2 = [["actc", 4], ["tttgggcc", 6], ["ct", 2]] lista_1 = [l[0].upper() for l in lista_2]
Soluzione:
[x for x in lista]: crea una copia dilista.[y for y in lista]: crea una copia dilista(identico a sopra).[y for x in lista]: invalida. (Sexrappresenta l’elemento della lista, cos’e’y?)["x" for x in lista]: crea una lista piena di stringhe"x"lunga quantolista. Il risultato sara’:["x", "x", ..., "x"].[str(x) for x in lista]: per ogni interoxinlista, lo converte in stringa constr(x)e mette il risultato nella lista che sta creando. Il risultato sara’:["0", "1", ..., "9"].[x for str(x) in lista]: invalida: la trasformazionestr(...)e’ nel posto sbagliato![x + 1 for x in lista]: per ogni interoxinlista, aggiunge uno conx + 1e mette il risultato nella lista che sta creando. Il risultato sara’:[1, 2, ..., 10].[x + 1 for x in lista if x == 2]: per ogni interoxinlistacontrolla se vale2. Se lo e’ mettex + 1nella lista che sta creando, altrimento lo scarta. Il risultato sara’:[3].
Soluzione:
dna = open("data/dna-fasta/fasta.1").readlines() print(" ".join(dna)) # Rimuovo l'intestazione: due alternative dna_no_intestazione = [riga for riga in dna if not riga[0].startswith(">")] dna_no_intestazione = [riga for riga in dna if riga[0] != ">"] # Si', ci sono caratteri di a capo o spazi print(["\n" in riga for riga in dna_no_intestazione]) print([" " in riga for riga in dna_no_intestazione]) # Rimuovo i caratteri a capo da tutte le righe dna_solo_seq = [riga.strip() for riga in dna_no_intestazione] # Ricontrollo per sicurezza: non ci sono caratteri # di a capo ne' spazi print(["\n" in riga for riga in dna_solo_seq]) print([" " in riga for riga in dna_solo_seq]) # Concateno tutte le righe di dna_solo_seq sequenza = "".join(dna_solo_seq) # Calcolo il numero di "C" e "G" num_c = sequenza.count("C") num_g = sequenza.count("G") # Calcolo il GC-content, facendo attenzione da usare # dei float per evitare errori di approssimazione gc_content = float(num_c + num_g) / len(sequenza)
Soluzione:
risultato_cdhit = """\ >Cluster 0 0 >YLR106C at 100.00% >Cluster 50 0 >YPL082C at 100.00% >Cluster 54 0 >YHL009W-A at 90.80% 1 >YHL009W-B at 100.00% 2 >YJL113W at 98.77% 3 >YJL114W at 97.35% >Cluster 52 0 >YBR208C at 100.00% """ righe = risultato_cdhit.split("\n")
Per ottenere i nomi dei cluster, devo tenere solo le righe che cominciano per
">", e per ciascuna di queste fare losplit()in modo da poter ottenere il secondo elemento (che e’ il nome del cluster):nomi_cluster = [riga.split()[1] for riga in righe if riga.startswith(">")]
Per ottenere i nomi delle proteine, devo tenere solo le righe che non cominciano per
">", e per ciascuna di queste fare losplit()e tenere il secondo elemento (avendo cura di rimuovere il">"dal nome della proteina):proteine = [riga.split()[1].lstrip(">") for riga in righe if not riga.startswith(">")]
Per ottenere le coppie proteina-percentuale, come nel caso precedente, tengo solo le righe che non cominciano per
">". Su ciascuna di queste facciosplit()e tengo il nome della proteina (secondo elemento) e la percentuale (ultimo elemento):coppie_proteina_percentuale = \ [[riga.split()[1].lstrip(">"), riga.split()[-1].rstrip("%")] for riga in righe if not riga.startswith(">")]
Versione annotata:
coppie_proteina_percentuale = \ [[riga.split()[1].lstrip(">"), riga.split()[-1].rstrip("%")] # ^^^^^^^^^^^^^^^^^^^^^^^^^^^ ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ # nome proteina, come sopra percentuale # ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ # coppia proteina-percentuale for riga in righe if not riga.startswith(">")]
Soluzione:
righe = open("data/prot-pdb/1A3A.pdb").readlines() # ~~~~ prima parte ~~~~ # Estraggo tutte le righe SEQRES righe_seqres = [riga for riga in righe if riga.startswith("SEQRES")] print(len(righe_seqres)) # 48 # Estraggo i nomi delle catene catene = [riga.split()[2] for riga in righe_seqres] print(catene) # Estraggo da righe_seqres quelle relative alla catena B righe_seqres_b = [riga for riga in righe_seqres if riga.split()[2] == "B"] print(len(righe_seqres_b)) # 12 # Estraggo le sequenze da ciascuna riga di righe_seqres_b, # poi concateno per ottenere il risultato voluto. sequenze_parziali_B = [" ".join(riga.split()[4:]) for riga in righe_seqres_b] sequenza_B = "".join(sequenze_parziali_B) # ~~~~ seconda parte ~~~~ # Estraggo tutte le righe HELIX righe_helix = [riga for riga in righe if riga.startswith("HELIX")] print(len(righe_helix)) # 30 # Estraggo dalle righe le posizioni di ciascuna elica eliche_inizio_fine = [[int(riga.split()[5]), int(riga.split()[8])] # ^^^^^^^^^^^^^^^^^^^^ ^^^^^^^^^^^^^^^^^^^^ # inizio elica fine elica for riga in righe_helix] # In un secondo passaggio (per comodita') calcolo # il risultato voluto info_eliche = [coppia + [coppia[1] - coppia[0] + 1] # ^^^^^^ ^^^^^^^^^^^^^^^^^^^^^^^^^^^ # [inizio, fine] lunghezza for coppia in eliche_inizio_fine]
Soluzione:
matrice = [list(range(0,3)), list(range(3,6)), list(range(6,9))] # estraggo la prima riga prima_riga = matrice[0] # estraggo la prima colonna prima_colonna = [matrice[0][i] for i in range(3)] # inverto l'ordine delle righe sottosopra = matrice[:] sottosopra.reverse() # oppure sottosopra = [matrice[2-i] for i in range(3)] # inverto l'ordine delle colonne palindromo = [] # appendo la prima riga di matrice invertita palindromo.append([matrice[0][2-i] for i in range(3)]) # appendo la seconda riga di matrice invertita palindromo.append([matrice[1][2-i] for i in range(3)]) # appendo la terza riga di matrice invertita palindromo.append([matrice[2][2-i] for i in range(3)]) # oppure in un solo passaggio -- ma e' complicato e potete ignorarlo!!! palindromo = [[riga[2-i] for i in range(3)] for riga in matrice] # ricreo matrice con una sola list comprehension matrice_di_nuovo = [list(range(i, i+3)) for i in range(9) if i % 3 == 0]
Soluzioni:
lista = list(range(100)) lista_quadrati = [numero**2 for numero in numeri] lista_differenze_quadrati = \ [lista_quadrati[i+1] - lista_quadrati[i] for i in range(len(lista_quadrati) - 1)]
Python: Fake Test¶
Giunti a questo punto, dovreste essere capaci di fare il seguente esercizio:
Esercizio¶
Scrivete un modulo python che data in input la sequente seq di DNA:
DNA = "tatgtaaactgccaaggtgaacgttggaatcacctcgtatgtgactcgcgtgtgacctggatactgtcaaaccaggtcaggaaagcctatgagtacgagc"
- conti le frequenze di a,c,g,t normalizzate (numero di occorrenze di a diviso lunghezza della stringa. Es: se ci sono 30 “a” e la stringa è lunga 60, la frequenaza normalizzata di “a” è uguale a 30/60 = 0.5)
- stampi il DNA ordinato (es “aaaaaaaaaccccccccgggggggttttt”)
- create un array chiamato array_DNA, contenente la frequenza del aminoacido corrisponedete. Es se le frequnze sono a=0.20,c=0.30,g=0.10,t=0.40, e il DNA è del tipo “atgc…”, dovete creare l’array [0.2,0.4,0.1,0.3,…]
- Create un array con la media mobile del array chiamato array_DNA. La media mobile è un array dove l’elemento in posizione i rappresenta la media degli elementi in posizione 0,1,2,..,i-1,i. Es se l’array in input è [1,1,4,5], l’array contenente le medie mobile è il seguente: [1,1,2,2.75] perche [1/1 = 1, (1+1)/2 = 1, (1+1+4)/3 = 2, (1+1+4+5)/4 = 2.75]
In fine stampate i 4 risultati, un esempio di output del programma è il seguente:
res1 freq a = 0.28 freq c = 0.27 freq g = 0.22 freq t = 0.23
res2 aaaaaaaaaaaaaaaaaaaaaaaaaaaaccccccccccccccccccc....
res3 [0.23, 0.28, 0.23, 0.27, 0.23 ...
res4 [0.23, 0.255, 0.24666666666666667, 0.2525, 0.248 ....
L’esercizio è interamente risolvibile con quello cha abbiamo fatto fino a qui
Soluzione¶
Definisco la variabile DNA copiando e incollando la stringa sopra:
DNA = "tatgtaaactgccaaggtgaacgttggaatcacctcgtatgtgactcgcgtgtgacctggatactgtcaaaccaggtcaggaaagcctatgagtacgagc"
per poter risolvere il punto 1 è sufficiente contare le sequenze con il metodo count delle stringhe, e dividere per la lunghezza del DNA (len(DNA)):
f_a = DNA.count("a")/len(DNA)
f_c = DNA.count("c")/len(DNA)
f_g = DNA.count("g")/len(DNA)
f_t = DNA.count("t")/len(DNA)
per concludere stampo il res 1:
print("res1: ",f_a,f_c,f_g,f_t)
Per quanto riguarda il punto 2, devo poter ordianre la stringa. Per l’ordinamento noi abbiamo visto il sort un metodo degli array. Quindi converto in array (con il list comprehension), ordino(con il metodo sort), e per finire ricreo la stringa (metodo join):
DNA_sort = [x for x in DNA] # converto la lista in stringa
DNA_sort.sort() # ordino la lista
string_dna_sort = "".join(DNA_sort) # riunisco la lista ordinata in una stringa
print("res2: ",string_dna_sort) # stampo la stringa
Il punto 3 sembra essere un pò più complesso, ma in realtà è molto semplice. Posso usare il replace per sostituire gli aminoacidi con le loro frequnze, io per semplicità ci ho aggiunto pure uno spazio vuoto (che mi servirà dopo per fare lo split!):
array_DNA = DNA.replace("a",str(f_a)+" ") # replace di a con la sua freq
array_DNA = array_DNA.replace("c",str(f_c)+" ") # replace di a con la sua freq
array_DNA = array_DNA.replace("g",str(f_g)+" ") # replace di a con la sua freq
array_DNA = array_DNA.replace("t",str(f_t)+" ") # replace di a con la sua freq
array_DNA = array_DNA.split(" ") # splitto la stringa e la trasformo in un array
array_DNA = array_DNA[:-1] # rimuovo l'ultimo elemento (perche è vuoto)
print("res3: ",array_DNA) # stampo il risultato
In fine, per poter calcolare la media mobile, posso calcolare prima la somma degli elementi precedenti:
sum_array_DNA = [sum(array_DNA[:x+1]) for x in range(len(array_DNA))]
in sum_array_DNA l’elemento i-esimo rappresenta la somma degli elementi dalla posizione 0 alla posizione i. Successivamente, posso calcolare la media mobile, dividendo l’ i-esimo elemento di sum_array_DNA per i:
media_mobile = [sum_array_DNA[x]/(x+1) for x in range(len(sum_array_DNA))]
Python: Dizionari¶
I dizionari rappresentano mappe tra oggetti: mappano una chiave nel valore corrispondente.
Warning
I dizionari sono mutabili!
Per definire un dizionario scrivo:
codice = {
"UUU": "F", # fenilalanina
"UCU": "S", # serina
"UAU": "Y", # tirosina
"UGU": "C", # cisteina
"UUC": "F", # fenilalanina
"UCC": "S", # serina
"UAC": "Y", # tirosina
# ...
}
Qui codice implementa il codice genetico, che mappa da stringhe di tre
lettere (le chiavi) al nome dell’aminoacido corrispondente (i valori).
La sintassi e’:
{ chiave1: valore1, chiave2: valore2, ...}
Uso un dizionario in questo modo:
aa_di_uuu = codice["UUU"]
print(aa_di_uuu) # "phenylalanine"
aa_di_ucu = codice["UCU"]
print(aa_di_ucu) # "serine"
PROVIAMO INSIEME
Posso usare questo dizionario per “simulare” il processo della traduzione. Ad esempio, partendo da una sequenza di mRNA:
rna = "UUUUCUUAUUGUUUCUCC"
la spezzo in triplette:
triplette = [rna[i:i+3] for i in range(0, len(rna), 3)]
ottenendo:
>>> print(triplette)
['UUU', 'UCU', 'UAU', 'UGU', 'UUC', 'UCC']
ed a questo punto posso fare:
proteina = "".join([codice[tripletta] for tripletta in triplette])
ottenendo:
>>> print(proteina)
"FSYCFS"
La differenza piu’ notevole rispetto alla vera traduzione e’ che il nostro codice non rispetta i codoni di terminazione, ma e’ un difetto correggibile.
Warning
Le chiavi non possono essere ripetute, i valori si’!
Nell’esempio sopra, ogni chiave e’ una tripletta ed e’ associata ad un unico valore, ma lo stesso valore puo’ essere associato a piu’ chiavi:
print(codice["UCU"]) # "S", serina
print(codice["UCC"]) # "S", serina
PROVATE VOI
Esempio. Creo un dizionario che mappa ogni aminoacido nel suo volume (approssimato, in Amstrong cubici):
volume_di = {
"A": 67.0, "C": 86.0, "D": 91.0,
"E": 109.0, "F": 135.0, "G": 48.0,
"H": 118.0, "I": 124.0, "K": 135.0,
"L": 124.0, "M": 124.0, "N": 96.0,
"P": 90.0, "Q": 114.0, "R": 148.0,
"S": 73.0, "T": 93.0, "V": 105.0,
"W": 163.0, "Y": 141.0,
}
# Stampo il volume della citosina
print(volume_di["C"]) # 86.0
print(type(volume_di["C"])) # float
Qui le chiavi sono di tipo str (immutabili) ed i valori sono dei float
(sempre immutabili).
Warning
Non ci sono restrizioni sul tipo degli oggetti che si possono usare come valori. Come chiavi invece si possono usare solo oggetti immutabili!
Riassumo in che modo possono essere usati i vari tipi:
| Tipo | Come chiavi | Come valori |
|---|---|---|
| bool | ✓ | ✓ |
| int | ✓ | ✓ |
| float | ✓ | ✓ |
| str | ✓ | ✓ |
| list | NO | ✓ |
| tuple | ✓ | ✓ |
| dict | NO | ✓ |
| set | NO | ✓ |
Si veda l’esempio seguente.
Esempio. Creo un dizionario che mappa da ogni aminoacido ad una lista di due proprieta’: massa e volume:
proprieta_di = {
"A": [ 89.09, 67.0],
"C": [121.15, 86.0],
"D": [133.10, 91.0],
"E": [147.13, 109.0],
# ...
}
# Stampo massa e volume dell'alanina
print(proprieta_di["A"]) # [89.09, 67.0]
print(type(proprieta_di["A"])) # list
Qui le chiavi sono str (immutabili) ed i valori sono list (mutabili).
Le liste non possono essere chiavi, infatti
Provo a creare il dizionario inverso (limitandomi al primo elemento per semplicita’):
da_proprieta_ad_aa = { [89.09, 67.0]: "A" }
Mi aspetto che questo dizionario mappi dalla lista:
[89.09, 67.0]
ad "A". Pero’ quando provo a crearlo Python da’ errore:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
# ^^^^^^^^^^^^^^^^^^^^^^^
# list e' mutabile!
Questo succede perche’ le chiavi hanno tipo list, che non e’ immutabile!
Per risolvere il problema posso usare, al posto di liste, delle tuple:
da_proprieta_ad_aa = {
( 89.09, 67.0): "A",
(121.15, 86.0): "C",
(133.10, 91.0): "D",
(147.13, 109.0): "E",
# ...
}
aa = da_proprieta_ad_aa[(133.10, 91.0)]
print(aa) # "D"
print(type(aa)) # str
Ora le chiavi sono tuple, immutabili, e va tutto bene.
PROVATE VOI
- Scrivete un dizionario con 4 chiavi (da 0 a 4), dove il valore rappresenta il quadrato della chiave
- iterate sulla seguente lista
- lista = [1,3,1,1,0,2]
- e stampate a video il valore del dizionario usando le chiavi che incontrate nella lista
- output 1,9,1,1,0,4
Operazioni¶
| Ritorna | Operatore | Significato |
|---|---|---|
int |
len(dict) |
Restituisce il numero di coppie chiave-valore |
object |
dict[object] |
Restituisce il valore associato ad una chiave |
| – | dict[object]=object |
Inserisce o sostituisce una coppia chiave-valore |
Esempio. Partendo dal dizionario vuoto:
codice = {}
print(codice) # {}
print(len(codice)) # 0
ricreo il dizionario del primo esempio inserendo a mano tutte le coppie chiave-valore:
codice["UUU"] = "F" # fenilalanina
codice["UCU"] = "M" # metionina
codice["UAU"] = "Y" # tirosina
# ...
print(codice)
print(len(codice))
Mi accorgo di avere fatto un errore qui sopra: "UCU" dovrebbe corrispondere
a "S" (serina), non a "M" (metionina). Come faccio a correggere l’errore?
Risposta: sostituendo il valore corrispondente alla chiave "UCU" con quello
corretto:
codice["UCU"] = "S" # serina
Qui alla chiave "UCU", che gia’ era nel dizionario, associo un nuovo valore
"S" (serina).
Warning
Se provo ad ottenere il valore di una chiave non presente nel dizionario:
>>> codice[":-("]
Python da’ errore:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: ":-("
# ^^^^^
# questa e' la chiave che non esiste
Metodi¶
| Ritorna | Metodo | Significato |
|---|---|---|
object |
dict.get(k, [default]) |
Resituisce il valore della chiave, oppure il default |
bool |
object in dict |
True se la chiave e’ nel dizionario |
dict_keys |
dict.keys() |
Restituisce una vista sulle chiavi |
dict_values |
dict.values() |
Restituisce una vista sui valori |
dict_items |
dict.items() |
Restituisce una vista sulle coppie chiave-valore |
Esempio. Partendo dal dizionario codice definito nel primo esercizio:
codice = {
"UUU": "F", # fenilalanina
"UCU": "S", # serina
"UAU": "Y", # tirosina
"UGU": "C", # cisteina
"UUC": "F", # fenilalanina
"UCC": "S", # serina
"UAC": "Y", # tirosina
# ...
}
posso ottenere le chiavi cosi’:
>>> chiavi = codice.keys()
>>> print(chiavi)
dict_keys(["UUU", "UCU", "UAU", ...])
ed i valori cosi’:
>>> valori = codice.values()
>>> print(valori)
dict_values(["F", "S", Y", "C", ...])
oppure sia chiavi che valori cosi’:
>>> coppie_chiave_valore = codice.items()
>>> print(coppie_chiave_valore)
dict_items([("UUU", "F"), ("UCU", "S"), ...])
Infine posso controllare se una certa chiave sta nel dizionario:
>>> print("UUU" in codice)
True
>>> print(":-(" in codice)
False
Warning
Non c’e’ alcuna garanzia che un dizionario preservi l’ordine in cui vengono inseriti gli elementi.
Ad esempio:
>>> d = {}
>>> d["z"] = "zeta"
>>> d["a"] = "a"
>>> d
{'a': 'a', 'z': 'zeta'}
>>> list(d.keys())
['a', 'z']
>>> list(d.values())
['a', 'zeta']
>>> list(d.items())
[('a', 'a'), ('z', 'zeta')]
Qui ho inserito prima "z" e poi "a", ma quando estraggo dal
dizionario d le chiavi, i valori e le coppie chiave-valore,
l’ordine in cui mi restituisce "z" ed "a" e’ invertito!
Esempio. Posso usare un dizionario per rappresentare un oggetto strutturato, ad esempio le proprieta’ di una catena proteica:
chain = {
"name": "1A3A",
"chain": "B",
"sequence": "MANLFKLGAENIFLGRKAATK...",
"num_scop_domains": 4,
"num_pfam_domains": 1,
}
print(chain["name"])
print(chain["sequence"])
print(chain["num_scop_domains"])
Scrivere a mano dizionari come questo e’ sconveniente, ma quando leggeremo informazioni da file (possibilmente da interi database biologici), avere sotto mano dizionari fatti cosi’ puo’ essere molto comodo.
(Soprattutto se sopra ci costruiamo algoritmi per analizzare in modo automatico i dati!)
Esempio. Dato il sequente testo in FASTA (accorciato per motivi di spazio) che descrive la sequenza primaria della retrotranscriptasi del virus HIV-1:
>2HMI:A|PDBID|CHAIN|SEQUENCE
PISPIETVPVKLKPGMDGPKVKQWPLTEEKIKALVEICTEMEKEGKISKI
NKRTQDFWEVQLGIPHPAGLKKKKSVTVLDVGDAYFSVPLDEDFRKYTAF
QSSMTKILEPFKKQNPDIVIYQYMDDLYVGSDLEIGQHRTKIEELRQHLL
VQPIVLPEKDSWTVNDIQKLVGKLNWASQIYPGIKVRQLSKLLRGTKALT
PSKDLIAEIQKQGQGQWTYQIYQEPFKNLKTGKYARMRGAHTNDVKQLTE
WWTEYWQATWIPEWEFVNTPPLVKLWYQLEKEPIVGAETFYVDGAANRET
AIYLALQDSGLEVNIVTDSQYALGIIQAQPDKSESELVNQIIEQLIKKEK
>2HMI:B|PDBID|CHAIN|SEQUENCE
PISPIETVPVKLKPGMDGPKVKQWPLTEEKIKALVEICTEMEKEGKISKI
NKRTQDFWEVQLGIPHPAGLKKKKSVTVLDVGDAYFSVPLDEDFRKYTAF
QSSMTKILEPFKKQNPDIVIYQYMDDLYVGSDLEIGQHRTKIEELRQHLL
VQPIVLPEKDSWTVNDIQKLVGKLNWASQIYPGIKVRQLSKLLRGTKALT
PSKDLIAEIQKQGQGQWTYQIYQEPFKNLKTGKYARMRGAHTNDVKQLTE
WWTEYWQATWIPEWEFVNTPPLVKLWYQLE
>2HMI:C|PDBID|CHAIN|SEQUENCE
DIQMTQTTSSLSASLGDRVTISCSASQDISSYLNWYQQKPEGTVKLLIYY
EDFATYYCQQYSKFPWTFGGGTKLEIKRADAAPTVSIFPPSSEQLTSGGA
NSWTDQDSKDSTYSMSSTLTLTADEYEAANSYTCAATHKTSTSPIVKSFN
>2HMI:D|PDBID|CHAIN|SEQUENCE
QITLKESGPGIVQPSQPFRLTCTFSGFSLSTSGIGVTWIRQPSGKGLEWL
FLNMMTVETADTAIYYCAQSAITSVTDSAMDHWGQGTSVTVSSAATTPPS
TVTWNSGSLSSGVHTFPAVLQSDLYTLSSSVTVPSSTWPSETVTCNVAHP
>2HMI:E|PDBID|CHAIN|SEQUENCE
ATGGCGCCCGAACAGGGAC
>2HMI:F|PDBID|CHAIN|SEQUENCE
GTCCCTGTTCGGGCGCCA
Le sequenza e’ presa dalla Protein Data Bank, struttura 2HMI.
PROVATE VOI Trasformate il testo sopra in un dizionario come quello seguente:
sequenze_2HMI = {
"A": "PISPIETVPVKLKPGMDGPKVKQWPLTEEKI...",
"B": "PISPIETVPVKLKPGMDGPKVKQWPLTEEKI...",
"C": "DIQMTQTTSSLSASLGDRVTISCSASQDISS...",
"D": "QITLKESGPGIVQPSQPFRLTCTFSGFSLST...",
"E": "ATGGCGCCCGAACAGGGAC",
"F": "GTCCCTGTTCGGGCGCCA",
}
Dato questo dizionario posso estrarre facilmente la sequenza di ogni singola catena della struttura 2HMI:
>>> print(sequenze_2HMI["F"])
"GTCCCTGTTCGGGCGCCA"
calcolare di quante catene e’ composta la struttura:
num_catene = len(sequenze_2HMI)
calcolare statistiche sulla co-occorrenza di aminoacidi, provare a predire le strutture secondarie, allineare le sequenze contro qualche database…
Esempio. I dizionari sono utili anche per descrivere istogrammi. Ad esempio, supponiamo di avere una sequenza:
seq = "GTCCCTGTTCGGGCGCCA"
Calcolo le proporzioni dei vari nucleotidi:
num_A = seq.count("A") # 1
num_T = seq.count("T") # 4
num_C = seq.count("C") # 7
num_G = seq.count("G") # 6
Voglio catturare questa informazione statistica in un istogramma. Lo implemento cosi’:
istogramma = {
"A": num_A / len(seq), # 1 / 18 ~ 0.06
"T": num_T / len(seq), # 4 / 18 ~ 0.22
"C": num_C / len(seq), # 7 / 18 ~ 0.38
"G": num_G / len(seq), # 6 / 18 ~ 0.33
}
A questo punto posso recuperare la proporzione dei vari nucelotidi dall’istogramma:
prop_A = istogramma["A"]
print(prop)
Posso anche verificare che l’istogramma definisca una distribuzione di probabilita’ (approssimata), cioe’ che la somma delle proporzioni dia 1:
print(istogramma["A"] + istogramma["C"] + ...)
Esempio. Possiamo codificare una rete (in questo esempio fittizia) di interazioni fisiche o funzionali tra proteine cosi’:
partners_di = {
"2JWD": ("1A3A",),
"1A3A": ("2JWD", "2ZTI", "3BLU"),
"2ZTI": ("1A3A", "3BLF"),
"3BLU": ("1A3A", "3BLF"),
"3BLF": ("3BLU", "2ZTI"),
}
che rappresenta la rete:
2JWD ---------- 1A3A ---------- 2ZTI
| |
| |
3BLU ---------- 3BLF
Qui partners_di["1A3A"], ad esempio, e’ una tupla dove abbiamo messo tutti
i binding partners della proteina 1A3A.
Possiamo usare questo dizionario per trovare tutti i binding partners dei binding partners di 1A3A, e oltre:
# Estraggo i partner di 1A3A
partners = partners_di["1A3A"]
# Estraggo i partner dei partner di 1A3A
partners_2_step = partners_di[partners[0]] + \
partners_di[partners[1]] + \
...
partners_di[partners[-1]]
# Estraggo i parner dei partner dei partner di 1A3A
partners_3_step = partners_di[partners_2_step[0]] + \
partners_di[partners_2_step[1]] + \
...
partners_di[partners_2_step[-1]]
La stessa struttura si puo’ usare per codificare reti sociali (Facebook, Twitter, Google+, etc.) e trovare chi e’ amico (o segue) chi, o per individuare comunita’ di persone che si conoscono tra loro.
Note
Ci sono molti altri modi di codificare reti. Un’alternativa al dizionario di cui sopra, e’ la matrice di adiacenza, che si puo’ implementare come una lista di liste.
Esercizi¶
Creare a mano:
Un dizionario vuoto. Controllare che sia vuoto con
len().Un dizionario
pronomiche rappresenta queste corrispondenze:1 -> "io" 2 -> "tu" 3 -> "egli" ...
Crearlo in due modi:
- In una sola riga di codice.
- Partendo da un dizionario vuoto ed aggiungendo passo passo tutte le coppie chiave valore.
Un dizionario
decuplo_diche implementa la funzione f(n) = 10 n, che associa ogni chiave (un intero) al suo decuplo.Le chiavi devono essere gli interi da 1 a 5.
Una volta costruito il dizionario, applicarlo a tutti gli elementi di
range(2, 5)con una list comprehension e stampare a schermo il risultato.Poi fare la stessa cosa, pero’ per tutte le chiavi di
decuplo_di.Hint: la vista sulle chiavi si puo’ ottenere con
keys().Un dizionario
info_2TMVche codifica informazioni strutturate sulla struttura PDB 2TMV della capside del Tobacco Mosaic Virus.- Alla chiave
"pdb_id"associate il valore"2TMV". - Alla chiave
"uniprot_id"associate il valore"P69687 (CAPSD_TMV)". - Alla chiave
"numero_domini_scp"associate1. - Alla chiave
"numero_domini_pfam"associate1.
- Alla chiave
Un dizionario
parenti_diche rappresenta questa rete:GIULIA ---- FRANCO ---- MATTEO | | + ----- BENEDETTA ------+
come nell’esempio visto in precedenza.
Una volta costruito il dizionario, stampare a schermo il numero di parenti di
"GIULIA".Un dizionario
da_2_bit_a_interoche rappresenta la mappa dalle seguenti coppie di interi ad intero:0, 0 -> 0 # 0*2**1 + 0*2**0 = 0 0, 1 -> 1 # 0*2**1 + 1*2**0 = 1 1, 0 -> 2 # 1*2**1 + 0*2**0 = 2 1, 1 -> 3 # 1*2**1 + 1*2**1 = 3 ^^^^ ^ ^^^^^^^^^^^^^^^^^^^ chiave valore spiegazione
Una volta creato il dizionario, stampare a schermo il valore corrispondente ad una delle quattro chiavi date (a scelta).
Dato:
rapporti = { ("A", "T"): 10.0 / 5.0, ("A", "C"): 10.0 / 7.0, ("A", "G"): 10.0 / 6.0, ("T", "C"): 5.0 / 7.0, ("T", "G"): 5.0 / 6.0, ("C", "G"): 7.0 / 6.0, }che rappresenta rapporti tra il numero di A, T, C, e G in una sequenza:
Che differenza c’e’ tra
len(rapporti),len(rapporti.keys()),len(rapporti.values())elen(rapporti.items())?Controllare se
rapporticontiene la chiave("T", "A"). E la chiave("C", "G")?Hint: posso usare
keys()? Posso usare un altro metodo?Controllare se contiene il valore 2. E il valore 3?
Hint: posso usare
values()?Controllare se contiene la coppia chiave-valore
(("A", "T"), 2). E la coppia chiave-valore(("C", "G"), 1000)?Hint: posso usare
items()?Usare una list comprehension per estrarre le chiavi dal risultato di
items(). Poi fare la stessa cosa con le chiavi.
Dato:
mappa = { "zero": 1, "uno": 2, "due": 4, "tre": 8, "quattro": 16, "cinque": 32, }Concatenare tutte le chiavi di
mappa, separate da spazi, in una sola stringastringa_delle_chiavi.Concatenare tutti i valori di
mappacome stringhe, separate da spazi, in una sola stringastringa_dei_valori.Hint: occhio che i valori di
mappanon sono stringhe!Mettere in una lista tutte le chiavi di
mappa.Mettere in una lista tutte le chiavi di
mappa, ordinate alfanumericamente.Hint: la vista restituita da
keys()e’ ordinata?Mettere in una lista tutti i valori di
mappa, ordinati in base all’ordine delle chiavi corrispondenti.Hint: come faccio ad ordinare una lista in base all’ordine di un’altra lista?
Dato:
traduzione_di = {"a": "ade", "c": "cyt", "g": "gua", "t": "tym"}tradurre la lista:
lista = ["A", "T", "T", "A", "G", "T", "C"]
nella stringa:
"ade tym tym ade gua tym cyt"
Hint: occhio che le chiavi del dizionario sono minuscole, mentre gli elementi di
listasono maiuscoli! Partite assumendo che non lo siano, poi modificate il codice per tenere conto di questa idiosincrasia.
Dizionari (Soluzioni)¶
Soluzioni:
Soluzione:
diz_vuoto = {} print(diz_vuoto) print(len(diz_vuoto)) # 0Soluzione:
pronomi = {} pronomi[1] = "io" pronomi[2] = "tu" pronomi[3] = "egli" pronomi[4] = "noi" pronomi[5] = "voi" pronomi[6] = "essi"oppure:
pronomi = { 1: "io", 2: "tu", 3: "egli", 4: "noi", 5: "voi", 6: "essi", }Soluzione:
decuplo_di = {1: 10, 2: 20, 3: 30, 4: 40, 5: 50} print([decuplo_di[n] for n in range(2, 5)]) print([decuplo_di[chiave] for chiave in decuplo_di.keys()])Soluzione:
info_2TMV = { "pdb_id": "2TMV", "uniprot_id": "P69687 (CAPSD_TMV)", "numero_domini_scp": 1, "numero_domini_pfam": 1, }Soluzione:
parenti_di = { "GIULIA": ["FRANCO", "BENEDETTA"], "FRANCO": ["GIULIA", "MATTEO"], "MATTEO": ["FRANCO", "BENEDETTA"], "BENEDETTA": ["GIULIA", "MATTEO"], } num_parenti_di_giulia = len(parenti_di["GIULIA"]) print(num_parenti_di_giulia)Soluzione:
da_2_bit_a_intero = { (0, 0): 0, (0, 1): 1, (1, 0): 2, (1, 1): 3, }Occhio che non posso usare delle liste come chiavi: le liste non sono immutabili!
Scelgo di stampare il valore corrispondente a 1, 0:
print(da_2_bit_a_intero[(1, 0)]) # ^^^^^^ # tupla
Soluzione:
rapporti = { ("A", "T"): 10.0 / 3.0, ("A", "C"): 10.0 / 7.0, ("A", "G"): 10.0 / 6.0, ("T", "C"): 3.0 / 7.0, ("T", "G"): 3.0 / 6.0, ("C", "G"): 7.0 / 6.0, } print(len(rapporti)) # 6 print(len(rapporti.keys())) # 6 print(len(rapporti.values())) # 6 print(len(rapporti.items())) # 6 # tutti contano il numero di coppie chiave-valore! # stampo le chiavi del dizionario per farmi un'idea print(rapporti.keys()) # e' una vista su tuple! print(type(rapporti.keys())) # dict_keys print(type(rapporti.keys()[0])) # tuple contiene_T_A = ("T", "A") in rapporti.keys() print(contiene_T_A) # False contiene_C_G = ("C", "G") in rapporti.keys() print(contiene_C_G) # True # posso fare la stessa cosa direttamente con l'oggetto dizionario: print(("T", "A") in rapporti) # False print(("C", "G") in rapporti) # True # stampo i valori del dizionario per farmi un'idea print(rapporti.values()) # e' una vista su interi! print(type(rapporti.values()[0])) # int contiene_2 = 2 in rapporti.values() print(contiene_2) # True contiene_3 = 3 in rapporti.values() print(contiene_3) # False # stampo le coppie chiave-valore per farmi un'idea print(rapporti.items()) # e' una vista su coppie (tuple): il primo elemento, la chiave, e' # una coppia esso stesso, il secondo e' un intero print((("A", "T"), 2) in rapporti.items()) # True print((("C", "G"), 1000) in rapport.items()) # False # le list comprehension sono chiavi = [chiave_valore[0] for chiave_valore in rapporti.items()] valori = [chiave_valore[-1] for chiave_valore in rapporti.items()]Soluzione:
mappa = { "zero": 1, "uno": 2, "due": 4, "tre": 8, "quattro": 16, "cinque": 32, } # le chiavi di mappa sono tutte stringhe, quindi keys() mi # restituisce una vista su stringhe: posso usare # direttamente join() stringa_delle_chiavi = " ".join(mappa.keys()) # i valori di mappa sono interi, quindi non posso usare # join() direttamente: devo prima trasformare tutti i # valori da interi a stringhe stringa_dei_valori = " ".join(str(valore) for valore in mappa.values()) vista_sulle_chiavi = mappa.keys() print(vista_sulle_chiavi) # non e' ordinata lista_ordinata_delle_chiavi = list(mappa.keys()) lista_ordinata_delle_chiavi.sort() print(lista_ordinata_delle_chiavi) # ora e' ordinata lista_dei_valori_ordinati_per_chiavi = \ [mappa[chiave] for chiave in lista_ordinata_delle_chiavi]Soluzione:
# usando una list comprehension posso applicare il dizionario # alla lista: qui e' necessario usare lower() *prima* di # usare un aminoacido come chiave di traduzione_di! traduzione = [traduzione_di[aa.lower()] for aa in lista] print(traduzione) # a questo punto posso usare join() per concatenare le varie # parti risultato = " ".join(traduzione) print(risultato)
oppure, in un solo comando:
print(" ".join([traduzione_di[aa.lower()] for aa in lista]))
Python: Sets¶
I set (insiemi) sono una collezione non ordinata di elementi senza ripetizioni.
Per definire un insieme, posso scrivere:
sette_nani = {"Brontolo", "Pisolo", "Dotto", ...}
I set possono essere visti come dizionari di sole chiavi.
La sintassi e’:
{ valore1, valore2, ...}
Posso creare un set vuoto utilizzando la funzione set:
empty_set = set()
print(type(empty_set)) # set
print(len(empty_set)) # 0
empty_set2 = {}
print(type(empty_set2)) # dict
La stessa funzione puo’ essere utilizzata per creare un set a partire da una lista:
set_numeri = set([1, 2, 3])
print(set_numeri) # {1, 2, 3}
- I set possono essere utilizzati per rimuovere le ripetizioni da una lista::
- lista = [0, 1, 0, 0, 2, 0] insieme = set(lista) print(insieme) # {0, 1, 2}
Operazioni¶
| Ritorna | Operatore | Significato |
|---|---|---|
int |
len(set) |
Restituisce il numero di elementi nel set |
bool |
object in set |
Controlla se l’elemento e’ presente nel set |
None |
set.add(object) |
Inserisce un elemento |
None |
set.update(list) |
Inserisce una lista di elementi |
None |
set.remove(object) |
Rimuove un elemento (errore se non presente) |
None |
set.discard(object) |
Rimuove un elemento |
Esempio. Partendo da un set vuoto:
numeri_fortunati = set()
print(numeri_fortunati) # set()
print(len(numeri_fortunati)) # 0
inserisco i primi cinque numeri naturali:
primi_cinque = range(5)
numeri_fortunati.update(primi_cinque)
print(len(numeri_fortunati)) # 5
inserisco i numeri pari tra 0 e 10 (incluso):
pari = [x for x in range(11) if x % 2 == 0]
numeri_fortunati.update(pari)
print(len(numeri_fortunati)) # 8
provo a rimuovere "0":
numeri_fortunati.discard("0") # non fa nulla
numeri_fortunati.remove("0") # errore
aggiungo la stringa "0" al set e controllo che sia presente:
numeri_fortunati.add("0")
"0" in numeri_fortunati # True
Warning
Come per i dizionari, c’e’ alcuna garanzia che un set preservi l’ordine in cui vengono inseriti gli elementi.
Warning
I set sono oggetti mutabili, come nel caso delle liste conviene prestare attenzione per evitare situazioni spiacevoli, ad esempio:
pasto_completo = {'antipasto', 'primo', 'secondo', 'dolce', "caffe'"}
pasto_ridotto = pasto_completo
pasto_ridotto.remove('antipasto', 'dolce')
print(pasto_completo)
{'primo', 'secondo', "caffe'"} # Doh!
Per creare una copia di un set:
L = {1, 2, 3}
copia_di_L = set(L)
copia_di_L.remove(2)
print(copia_di_L) # {1, 3}
print(L) # {1, 2, 3}
PROVATE VOI Esercizi
- Creare:
- Un set vuoto
set_vuoto. Controllare che sia vuoto conlen(). - Un set
primi10contenente i primi 10 numeri naturali. Controllare se contiene 10, in caso contrario, inserirlo e ricontrollare che sia presente. Rimuoverlo nuovamente. - Un set
primi10no7contenente i primi 10 numeri naturali, tranne 7 (partendo daprimi10ma lasciandolo inalterato). Controllo che 7 sia presente inprimi10e assente inprimi10no7. - Ricreare
primi10no7, questa volta utilizzando una list comprehension.
- Un set vuoto
Operazioni¶
| Ritorna | Operatore | Significato |
|---|---|---|
set |
set.union(set) |
Restituisce l’unione di due set |
set |
set.intersection(set) |
Restituisce l’intersezione tra due set |
set |
set.difference(set) |
Restituisce la differenza tra due set |
Esempio. Creo il set dei primi dieci numeri naturali:
set_A = set(range(10))
Creo il set dei multipli di 3 compresi tra 0 e 20:
set_B = set([x for x in range(20) if x % 3 == 0])
Creo l’unione di set_A e set_B:
unione = set_A.union(set_B)
print(unione) # {0, 1, 2, 3, .., 8, 9, 12, 15, 18}
Ora creo l’intersezione di set_A e set_B:
intersezione = set_A.intersection(set_B)
print(intersezione) # {0, 3, 6, 9}

Nota: le operazioni di unione e intersezione sono simmetriche, per qualsiasi set_A e set_B vale:
set_A.union(set_B) == set_B.union(set_A) # True
set_A.intersection(set_B) == set_B.intersection(set_A) # True
Ottengo i numeri naturali tra 0 e 9 che NON sono multipli di 3:
diff1 = set_A.difference(set_B)
print(diff1) # {1, 2, 4, 5, 7, 8}

Analogamente, ottengo i multipli di 3 fino al 18 che NON sono compresi tra 0 e 9:
diff2 = set_B.difference(set_A)
print(diff2) # {12, 15, 18}
Nota al contrario di unione ed intersezione, la differenza non e’ simmetrica!
Esercizi¶
Per ogni testo, creare l’insieme delle parole che contiene (maiuscole/minuscole non contano):
testo_A = "Le due ore di informatica piu' noiose della vostra vita" testo_B = "La vita e' come una scatola di cioccolatini" testo_C = "Cioccolatini come se piovesse LA La lA laaa"
- Contare il numero di parole diverse per ognuno dei tre testi.
- Ottenere gli insiemi delle parole in comune tra i tre testi:
condivise_A_B,condivise_A_C,condivise_B_C. - Dati i set creati precedentemente, ottenere l’insieme delle parole che compaiono in almeno due testi, utilizzando soltanto operazioni tra set.
- Ottenere l’insieme delle parole che compaiono esattamente in un testo. Hint posso farlo utililizzando il risultato precedente?
- Ottenere l’insieme delle parole che compaiono ripetute nello stesso testo.
Soluzioni¶
Soluzioni:
Soluzione:
set_vuoto = {} print(set_vuoto) print(len(set_vuoto)) # 0Soluzione:
primi10 = set(range(10)) print(10 in primi10) # False primi10.add(10) print(10 in primi10) # True primi10.remove(10)
Soluzione, provo cosi’:
primi10no7 = primi10 primi10no7.remove(7) print(7 in primi10) # False
Ricordo che i set sono strutture mutabili:
primi10 = set(range(10)) # Ricreo il set originale primi10no7 = set(primi10) primi10no7.remove(7) print(7 in primi10) # True print(7 in primi10no7) # False
Soluzione:
primi10no7 = set([x in range(10) if x != 7]) print(primi10no7) # Controllo
Soluzione:
Convertendo i testi in minuscolo:
tA_lower = testo_A.lower() tB_lower = testo_B.lower() tC_lower = testo_C.lower()
Creo gli insiemi delle parole contenute nei testi:
parole_in_A = set(tA_lower.split()) parole_in_B = set(tB_lower.split()) parole_in_C = set(tC_lower.split())
Conto per ogni testo il numero di parole diverse:
len(parole_in_A) # 10 len(parole_in_B) # 8 len(parole_in_C) # 6
Ottengo le parole in comune utilizzando l’intersezione:
condivise_A_B = parole_in_A.intersection(parole_in_B) condivise_A_C = parole_in_A.intersection(parole_in_C) condivise_B_C = parole_in_B.intersection(parole_in_C)
Controllo:
print(condivise_A_B) # {'vita', 'di'} print(condivise_A_C) # set() print(condivise_B_C) # {'la', 'cioccolatini', 'come'}Soluzione:
almeno_in_2 = condivise_A_B.union(condivise_A_C).union(condivise_B_C) print(almeno_in_2) # {'vita', 'di', 'la', 'cioccolatini', 'come'}Creo l’insieme di tutte le parole contenute nei tre testi:
tutte_le_parole = parole_in_A.union(parole_in_B).union(parole_in_C)
Ottengo le parole che appaiono esattamente in **UN* testo:
solo_in_uno = tutte_le_parole.difference(almeno_in_2) print(solo_in_uno) {'le', 'una', 'se', 'vostra', 'della', 'laaa', "piu'", 'ore', "e'", \ 'piovesse', 'scatola', 'noiose', 'informatica', 'due'}Ci sono diversi modi per farlo. Una soluzione (consideriamo solo testo_A per brevita’):
ripetute_in_A = set([p for p in parole_in_A \ if tA_lower.count(p) > 1])
Python: Tuple¶
Le tuple sono liste immutabili.
Per definire una tupla uso le parentesi tonde:
partners = ("BIOGRID:112315", "BIOGRID:108607")
Esempio. Se voglio creare una tupla con un solo elemento (puo’ capitare…) devo ricordarmi di usare la virgola, oltre alle parentesi tonde:
tupla = (0,)
print(tupla)
print(type(tupla))
print(len(tupla))
non_tupla = (0)
print(non_tupla)
print(type(non_tupla))
Come si vede, non_tupla e’ un intero, 0.
Operazioni¶
| Ritorna | Operatore | Significato |
|---|---|---|
int |
len(tuple) |
Restituisce la lunghezza della tuple |
tuple |
tuple + tuple |
Concatena le due tuple |
tuple |
tuple * int |
Replica la tupla |
bool |
object in tuple |
Contolla se un oggetto arbitrario appare nella tupla |
tuple |
tuple[int:int] |
Estrae una sotto-tupla |
Le tuple supportanto tutti gli operatori delle stringhe e delle liste, tranne l’assegnamento.
Esempio. Creo una tupla con elementi misti:
proteina = ("2B0Q", "phosphotransferase", "PF03881")
che contiene informazioni su una proteina. Posso accedere ai vari elementi come farei con una lista:
id_proteina = proteina[0]
print(id_proteina)
nome_proteina = proteina[1]
print(nome_proteina)
Pero’ non posso modificare la tupla:
>>> proteina[0] = "1A3A"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
Esempio. Proprio come le liste e gli intervalli, posso usare le tuple come input ad una list comprehension:
tripla = (1, 2, 3)
risultato = [2*numero for numero in tripla]
print(risultato)
print(type(risultato))
Il risultato di una list comprehension e’ comunque una lista.
Metodi¶
| Ritorna | Metodo | Significato |
|---|---|---|
int |
tuple.index(object) |
Restituisce la posizione di object. |
int |
tuple.count(object) |
Conta il numero di ripetizioni di un valore |
Conversione Lista-Tupla¶
Per convertire tra liste e tuple uso tuple() e list():
lista = list(range(10))
tupla = tuple(lista)
print(tupla, type(tupla))
lista_2 = list(tupla)
print(lista_2, type(lista_2))
Ne segue che se proprio voglio “modificare” una tupla posso scrivere:
tupla = ("sono", "una", "tupla")
print(tupla)
copia = list(tupla)
copia.insert(2, "bella")
tupla = tuple(copia)
print(tupla)
In realta’ quello che ottengo e’ una nuova tupla che contiene gli elementi della vecchia tupla in aggiunta a …
Esercizi¶
Creare:
Una tupla di due interi di valore
0e1.Una tupla di due stringhe,
"una"e"tupla".Una tupla di un solo elemento,
0.Hint: ci sono due modi di farlo: usare la sintassi vista all’inzio del capitolo, oppure usare la conversione lista-tupla.
Una tupla di cento elementi: i numeri interi da
0a99.Hint: posso usare (indirettamente)
range()?Una tupla con due elementi: la lista degli interi da
0a49e la lista degli interi da50a99.Una tupla con due elementi: la tupla degli interi da
0a49e la tupla degli interi da50a99.
Date
l = [0, 1, 2]et = (0, 1, 2), che differenza c’e’ tra:Primo caso:
x = l x[0] = 100
Secondo caso:
x = t x[0] = 100
Data la tupla:
tupla = (0, 1, 2, [3, 4, 5], 6, 7, 8)
- Di che tipo e’ il primo elemento della tupla? Quanto vale?
- Di che tipo e’ il quarto elemento della tupla? Quanto vale?
- Quanti elementi contiene la tupla?
- Quanti elementi contiene la lista contenuta nella tupla?
- Cambiare l’ultimo elemento della lista contenuta in
tuplain"ultimo". - Cambiare l’ultimo elemento di
tuplain"ultimo". (Si puo’ fare?)
Soluzioni¶
Soluzioni:
coppia_di_interi = (0, 1) print(type(coppia_di_interi)) # tuple coppia_di_stringhe = ("una", "tupla") print(type(coppia_di_stringhe)) # tuple un_solo_elemento = (0,) print(type(un_solo_elemento)) # tuple print(len(un_solo_elemento)) # 1 un_solo_elemento_alt = tuple([0]) print(type(un_solo_elemento_alt)) # tuple print(len(un_solo_elemento_alt)) # 1 sbagliato = (0) print(type(sbagliato)) # int print(len(sbagliato)) # errore! cento_elementi = tuple(range(100)) print(type(cento_elementi)) # tuple coppia_di_liste = (range(50), range(50, 100)) print(type(coppia_di_liste)) print(type(coppia_di_liste[0])) coppia_di_tuple = (tuple(range(50)), tuple(range(50, 100))) print(type(coppia_di_tuple)) print(type(coppia_di_tuple[0]))Soluzioni:
l = [0, 1, 2] t = (0, 1, 2) # x si riferisce ad una lista, il codice sostituisce # il primo elemento con 100 x = l x[0] = 100 # x ora si riferisce ad una tupla, che e' immutabile: # non posso sostituire i suoi elementi, Python da' # errore x = t x[0] = 100 # errore!
Soluzioni:
tupla = (0, 1, 2, [3, 4, 5], 6, 7, 8) print(tupla[0]) # 0 print(type(tupla[0])) # int print(tupla[3]) # [3, 4, 5] print(type(tupla[3])) # list print(len(tupla)) # 9 print(len(tupla[3])) # 3 tupla[3][-1] = "ultimo" print(tupla) # ebbene lo posso fare! ho "modificato" la # tupla modificando la lista contenuta # in essa. tupla[-1] = "ultimo" # errore! # non posso modificare la tupla "direttamente" # e' un oggetto immutabile
Python: Input-Output¶
Interfaccia Utente¶
| Ritorna | Operatore | Significato |
|---|---|---|
str |
input([str]) |
Fa una domanda all’utente e restituisce la risposta |
Esempio. Faccio una domanda all’utente:
risposta = input("scrivi tre parole separate da spazi: ")
print(risposta)
print(type(risposta))
Ho messo nella variabile risposta la risposta dell’utente (che e’ sempre
una stringa). Il contenuto di risposta dipende dall’utente, che potrebbe
aver dato una risposta qualunque.
Voglio controllare che abbia effettivamente risposto con tre parole separate da spazi:
parti = parole.split()
print("hai scritto", len(parti), "parole")
reazione_a = {True: "bravo!", False: "impegnati di piu'"}
print(reazione_a[len(parti) == 3])
Esempio. Faccio una domanda all’utente:
risposta = input("scrivi due numeri: ")
print(risposta)
print(type(risposta))
Voglio stampare la somma dei numeri dati dall’utente. Prima estraggo le varie
parole, poi le converto in float, poi eseguo la somma e la stampo:
parti = risposta.split()
numero_1 = float(parti[0])
numero_2 = float(parti[1])
print("la loro somma e'", numero_1 + numero_2)
Esercizi¶
Usando
input(), chiedere all’utente il suo piatto preferito, mettere il risultato in una variabilecibo, poi stampare a schermo:anche a me piaceed il piatto preferito.Chiedere all’utente due interi, diciamo
aeb, poi un terzo intero, diciamorisultato.Controllare se la somma di
aebe’ uguale arisultato: in tale caso stampare a schermoTrue, altrimentiFalse.Chiedere all’utente una chiave ed un valore, e costruire un dizionario che include (solo) quella coppia chiave-valore. Stampare a schermo il risultato.
Chiedere all’utente il suo nome, metterlo nella variabile
nome, poi stampare a schermo il nome assicurandosi che le prime lettere di tutte le parole del nome siano maiuscole e le altre minuscole.Infine stampare a schermo il risultato.
Interfaccia Filesystem¶
| Ritorna | Operatore | Significato |
|---|---|---|
file |
open(str, [str]) |
Restituisce un riferimento ad un file |
str |
file.read() |
Legge i contenuti del file |
str |
file.readline() |
Legge una riga dal file |
list-of-str |
file.readlines() |
Legge tutte le righe del file |
int |
file.write(str) |
Scrive una stringa nel file |
| – | file.close() |
Chiude il riferimento ad un file |
Ci sono diverse modalita’ di accesso usabili con open():
"r": modalita’ di sola lettura (non posso scrivere nel file). Questo e’ il default."w": modalita’ di sola scrittura (non posso leggere dal file), sovrascrivendo."a": modalita’ di sola scrittura (non posso leggere dal file), appendendo."+": modificatore per update (lettura/scrittura).
Esempio. Apro un file in modalita’ di lettura:
un_file = open("data/aatable", "r")
print(type(un_file)) # file
Il primo argomento e’ il percorso al file che voglio aprire (in questo caso
un percorso relativo alla directory da cui ho fatto partire python), il
secondo "r"" specifica in che modalita’ aprire il file.
Warning
Non potete usare directory speciali, ad esempio "~" (la vostra home)
nel percorso che date a open().
Esempio. Una volta aperto un file:
un_file = open("data/aatable", "r")
leggo i contenuti o per intero, in un’unica stringa:
contenuti = un_file.read()
print(contenuti)
print(type(contenuti))
oppure per intero ma spezzati in una lista di righe:
righe = un_file.readlines()
print(righe)
print(type(righe))
oppure una sola riga alla volta, dalla prima in giu’:
riga_1 = un_file.readline()
riga_2 = un_file.readline()
riga_3 = un_file.readline()
print(riga_1)
print(riga_2)
print(riga_3)
Warning
Una volta aperto un file, non posso leggere due volte la stessa riga.
Questo vuol dire che una volta che ho letto tutto il file, ad esempio
usando readlines() (che legge tutto il contenuto), se uso una
seconda volta readlines() o qualunque altro metodo di lettura,
questa mi restituira’ una riga vuota.
Ad esempio:
un_file = open("data/aatable", "r")
# non ho ancora letto niente, quindi readlines() mi
# restituisce tutti i contenuti del file
contenuti = un_file.readlines()
print(len(contenuti))
# ora che ho letto tutti i contenuti, non resta piu' niente
# da leggere, e infatti...
contenuti_2 = un_file.readlines()
print(len(contenuti_2))
# qui contenuti_2 ha ZERO righe
Visto che il file e’ stato aperto con open() in modalita’ di sola lettura,
non posso scriverci dentro:
un_file.write("del testo\n")
perche’ Python mi da’ errore:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IOError: File not open for writing
# ^^^^^^^^^^^^^^^^^^^^^^^^^
# il file non e' aperto in modalita' di scrittura!
La stessa cosa accade se provo a leggere da un file aperto in modalita’ di
sola scrittura (sia con "w" che con "a").
Esempio. Per aprire un file in cui mettere i risultati di un lunghissimo calcolo:
file_dei_risultati = open("risultati", "w")
# blah blah blah
# blah blah blah
# blah blah blah
file_dei_risultati.close()
Una volta finito di leggere o scrivere, chiamo close().
Warning
Per i file aperti in modalita’ di scrittura (con "w", "r+",
"a", …), close() si assicura che tutto cio’ che avete detto a
Python di scriverci effettivamente finisca per essere scritto nel file.
Se dimendicate di chiamare close() la scrittura nel file potrebbe
non accadere.
Esempio. Chiedo all’utente il nome di un file (che puo’ esistere o meno), e poi cosa vuole scriverci:
percorso = input("dove vuoi scrivere? ")
testo = input("cosa vuoi scrivere? ")
il_file = open(percorso, "w")
il_file.write("l'utente ha scritto:\n" + testo)
il_file.close()
Ora riapro lo stesso file, ma in modalita’ di lettura, ne leggo i contenuti e li stampo a schermo:
stesso_file = open(percroso, "r")
contenuti = stesso_file.read()
stesso_file.close()
print("Nel file ", percorso, " hai scritto:")
print(contenuti)
Esercizi¶
Warning
Se open() vi da’ errore, puo’ darsi che vi troviate nella directory
sbagliata. Aggiustate il percorso di conseguenza.
Usate
open()per aprire il file"data/aatable"in modalita’ di sola lettura, mettendo il risultato diopen()nella variabilef.Poi usate
readlines()per leggere il contenuto del file, mettendo il risultato inrighe.Di che tipo e’
righe? Di che tipo e’ il primo elemento dirighe? Quante righe ci sono nel file?Usate
open()per aprire il file"data/aatable"in modalita’ di sola lettura, mettendo il risultato diopen()nella variabilef.Poi usate
readline()(nonreadlines()!) per leggere la prima riga del file, mettendo il risultato inprima_riga.Quante righe sono rimaste da leggere? Controllate usando
readlines().A questo punto, quante altre righe sono rimaste da leggere?
Usate
open()per aprire il file"output.txt"in modalita’ di sola scrittura"w", mettendo il risultato diopen()nella variabilef.Poi scrivete la stringa
"prova prova uno due tre prova"nel file.Chiudete il file usando il metodo
close().Ora invece aprite
"output.txt"in modalita’ di sola lettura e stampate a schermo i suoi contenuti.usate
open()per aprire il file"poesia.txt"in modalita’ di sola scrittura. Poi scrivete nel file le stringhe in questa lista, una per riga:versi = [ "S'i fosse fuoco, arderei 'l mondo" "s'i fosse vento, lo tempestarei" ]Ora fare la stessa cosa aprendo due volte il file
"poesia2.txt"in modalita’ di sola scrittura (appendendo), ed ogni volta scrivendoci uno dei due versi.Cosa succede se riapro
"poesia2.txt"in modalita’"w"e lo richiudo subito?Scrivere un modulo
trucco.pyche stampa il codice del modulo stesso a schermo.Curiosita’: abbiamo appena scritto (barando!) un programma di Quine.
Python: Statement Complessi¶
Codice condizionale: if¶
if/elif/else (se/altrimenti-se/altrimenti) permettono di
scrivere codice che viene eseguito solo se una condizione e’ soddisfatta:
if condizione:
print("la condizione e' vera")
oppure di gestire separatamente i due casi soddisfatta/non soddisfatta:
if condizione:
print("la condizione e' vera")
else:
print("la condizione e' falsa")
oppure n casi diversi:
if condizione_1:
print("la prima condizione e' vera")
elif condizione_2:
print("la seconda condizione e' vera")
elif condizione_3:
print("la terza condizione e' vera")
else:
print("nessuna condizione e' vera")
L’if, gli elif e l’else formano una “catena”: sono mutualmente
esclusivi, solo uno tra loro viene eseguito!
Esempio. Il codice in un elif ed else e’ mutualmente
esclusivo con quello dei vari if ed elif che lo precedono.
Ad esempio, supponiamo di avere due variabili Boolean c1 e c2.
Guardiamo in dettaglio in che caso vengono eseguite le varie righe di codice
nell’ultimo esempio:
# c1 c2 | c1 c2 | c1 c2 | c1 c2
# True True | True False | False True | False False
# ----------|------------|------------|------------
print("inizio") # si | si | si | si
if c1: # si | si | si | si
print("1") # si | si | no | no
elif c2: # no | no | si | si
print("2") # no | no | si | no
else: # no | no | no | si
print("0") # no | no | no | si
print("fine") # si | si | si | si
E’ chiaro che se c1 e’ vera, il valore di c2 (ed il corrispondente
elif c2) non influenza il comportamento del programma: se l’if viene
eseguito (cioe’ se c1 e’ vera) gli elif ed else successivi non
vengono neanche considerati!
Supponiamo di voler stampare "1" se c1 e’ vera, ed anche "2" se
c2 e’ vera – in modo del tutto indipendente. Posso fare cosi’:
print("inizio")
if c1:
print("1")
if c2:
print("2")
if not c1 and not c2:
print("0")
print("fine")
Qui gli if non formano una “catena”: sono indipendenti l’uno dall’altro!
Esempio. Python usa l’indentazione per decidere quale codice fa parte
dell’if e quale no.
Scrivo un programma Python per testare se l’utente e’ un telepate:
print("sto pensando ad un numero tra 1 e 10...")
telepate = int(input("qual'e'? ")) == 72
print("sto calcolando...")
if telepate:
print("DING DING DING DING!")
print("COMPLIMENTI!")
print("sei un telepate certificato!")
else:
print("grazie per aver giocato")
print("riprova di nuovo")
print("fine.")
Come si vede eseguendo l’esempio con l’interprete, Python considera dentro
l’if tutti i print() indentati.
Esempio. Questo codice apre un file e controlla (i) se e’ vuoto, e (ii)
se contiene intestazioni (righe che cominciano per ">"), reagendo di
conseguenza:
print("comincio...")
righe = open("data/prot-fasta/1A3A.fasta").readlines()
if len(righe) == 0:
print("il file FASTA e' vuoto")
else:
primi_caratteri_di_ogni_riga = [riga[0] for riga in righe]
if not (">" in primi_caratteri_di_ogni_riga):
print("il file FASTA non e' valido")
else:
print("il file FASTA e' valido")
print("fatto!")
Quiz:
- E’ possibile che il codice stampi sia che il file e’ vuoto, sia che e’ valido?
- E’ possibile che il codice non stampi
"comincio..."o"fatto!"?- Se il file e’ effettivamente vuoto, quando Python esegue la riga
print("fatto!"), che valore ha la variabileprimi_caratteri_di_ogni_riga?- Posso semplificare il codice usando
elif?
Esercizi¶
Warning
Non dimenticate i due punti!
Se provo a scrivere un if e dimentico i due punti, es.:
>>> condizione = input("Dimmi si: ") == "si"
>>> if condizione
appena premo invio, Python mi dice che la sintassi e’ errata:
File "<stdin>", line 1
if condizione
^
SyntaxError: invalid syntax
e si rifiuta di eseguire il codice. Quindi e’ facile riconoscere l’errore.
Warning
State attenti all’indentazione!
Sbagliare l’indentazione modifica il comportamento del programma senza pero’ renderlo necessariamente invalido.
In alcuni casi e’ facile capire cosa sta succedendo, es.:
>>> condizione = input("Dimmi si: ") == "si"
>>> if condizione:
>>> print("hai detto:")
>>> print("si")
Python da’ errore immediatamente:
File "<stdin>", line 4
print("si")
^
IndentationError: unexpected indent
In altri invece l’errore e’ molto piu’ sottile. Vedi sezione su codice annidato.
Chiedere all’utente un numero con
input(). Se il numero e’ pari, stampare"pari"a schermo, se e’ dispari, stampare"dispari".Hint.
input()restituisce sempre una stringa.Chiedere all’utente un numero razionale. Se il numero e’ nell’intervallo [-1,1], stampare
"okay", altrimenti non stampare niente.Hint. E’ necessario usare
elif/else?Chiedere all’utente due numeri interi. Se il primo e’ maggiore del secondo, stampare
"primo", se il secondo e’ maggiore del primo stampare"secondo", altrimenti stampare"nessuno dei due".Dato il dizionario:
oroscopo_di = { "gennaio": "fortuna estrema", "febbraio": "fortuna galattica", "marzo": "fortuna incredibile", "aprile": "ultra-fortuna", }chiedere all’utente il suo mese di nascita. Se il mese appare come chiave nel dizionario
oroscopo_di, stampare a schermo il valore corrispondente. Altrimenti stampare"non disponibile".Hint. Per controllare se una chiave appare in un dizionario si puo’ usare
key in dict.Chiedere all’utente il percorso ad un file e leggere i contenuti del file con il metodo
readlines(). Poi stampare:- Se il file e’ vuoto, la stringa
"vuoto" - Se il file ha meno di 100 righe,
"piccolo"e il numero di righe. - Se il file ha tra le 100 e le 1000 righe,
"medio"e il numero di righe. - Altrimenti,
"grande"e il numero di righe.
La risposta deve essere stampata su una sola riga.
- Se il file e’ vuoto, la stringa
Chiedere all’utente due triplette di razionali (usando due chiamate a
input()). Le due triplette rappresentano due punti nello spazio tridimensionale (tre coordinate x,y,z a testa).Se tutte le coordinate sono non-negative, stampare a schermo la distanza Euclidea dei due punti.
Hint: la distanza Euclidea e’ \sqrt{(x_1 - x_2)^2 + (y_1 - y_2)^2 + (z_1 - z_2)^2}
E’ possibile che questo codice:
numero = int(input("scrivi un numero: ")) if numero % 3 == 0: print("divide 3!") elif numero % 3 != 0: print("non divide 3!") else: print("boh")stampi
"boh"?E’ possibile che questo codice:
numero = int(input("scrivi un numero: ")) if numero % 2 == 0: print("divide 2!") if numero % 3 == 0: print("divide 3!") if numero % 2 != 0 and numero % 3 != 0: print("boh")stampi
"boh"?Chiedere all’utente se vuole eseguire una somma o un prodotto.
Se l’utente vuole eseguire una somma, chiedere due numeri, effettuare la somma, e stampare il risultato.
Idem se l’utente vuole eseguire un prodotto.
Se l’utente non risponde ne’
"somma"ne’"prodotto", non fare niente.
Codice iterativo: for¶
for permette di scrivere codice che viene ripetuto (una ed una sola volta)
per ciascun elemento di una collezione (stringa, lista, tupla, dizionario).
La sintassi di for e’:
collezione_di_oggetti = range(10) # ad esempio
for elemento in collezione_di_oggetti:
codice_che_fa_qualcosa_con_elemento(elemento)
Questo ciclo for esegue codice_che_fa_qualcosa_con_elemento() per
ciascun elemento in collezione_di_oggetti, in ordine dal primo all’ultimo.
elemento e’ una variabile Python che prende il valore di ciascun elemento
di collezione_di_oggetti, dal primo all’ultimo: viene “creata” sul momento
quando scriviamo il ciclo for.
Proprio come con le list comprehension, il nome che le diamo e’ arbitrario.
Warning
Se collezione_di_oggetti e’ un dizionario, for itera sulle chiavi.
Occhio che l’ordine delle chiavi in un dizionario non e’ ovvio. Si veda sopra la sezione sui dizionari.
Esempio. Questo ciclo for:
lista = [1, 25, 6, 27, 57, 12]
for numero in lista:
print(numero)
itera su tutti gli elementi del risultato di lista: prima l’elemento 1,
poi l’elemento 25, etc., fino a 12, e li stampa nell’ordine in
cui appaiono nella lista.
Ad ogni iterazione il valore dell’elemento corrente viene automaticamente
messo nella variabile numero, mentre il print ne stampa il valore.
Posso ottenere lo stesso comportamento anche senza il ciclo for, cosi’:
numero = lista[0] # prima iterazione
print(numero)
numero = lista[1] # seconda iterazione
print(numero)
numero = lista[2] # terza iterazione
print(numero)
# ...
numero = lista[5] # ultima iterazione
print(numero)
Il for permette di compattare questo codice in due sole righe.
Esempio. Piuttosto che stampare gli elementi della lista, voglio stampare la loro somma.
Modifico il for dell’esempio sopra:
lista = [1, 25, 6, 27, 57, 12]
somma = 0
for numero in lista:
somma = somma + numero
print("la somma e'", somma)
Ho creato una variabile di supporto somma che inizializzo a 0.
Poi scorro su tutti i numeri contenuti in lista, e man mano li aggiungo a
somma.
Una volta terminato il ciclo for, somma varra’ (per costruzione):
lista[0] + lista[1] + ... + lista[-1]
che e’ esattamente la somma degli elementi.
Esempio. Piuttosto che calcolare la somma degli elementi della lista, voglio trovare il massimo.
L’idea e’ questa:
- Itero la lista con un
for. - Creo una nuova variabile
massimo_fino_ad_orain cui memorizzo l’elemento piu’ grande che ho trovato fino ad ora. Il valore viene aggiornato ad ogni iterazione del ciclofor. - Per ogni elemento della lista (cioe’ in ogni iterazione del
for) controllo se l’elemento che ho sotto mano e’ piu’ grande dimassimo_fino_ad_ora:- Se non lo e’, non faccio niente.
- Se lo e’, aggiorno
massimo_fino_ad_ora.
- Quando il
foravra’ finito di scorrere sugli elementi della lista,massimo_fino_ad_oraconterra’ (suspance!) il massimo elemento trovato fino ad ora.
PROVATE VOI
Esempio. Data la seguente tabella (che potrebbe essere il risultato
di readlines() su un file):
tabella = [
"protein domain start end",
"YNL275W PF00955 236 498",
"YHR065C SM00490 335 416",
"YKL053C-A PF05254 5 72",
"YOR349W PANTHER 353 414",
]
voglio convertirla in un dizionario fatto cosi’:
dati = {
"YNL275W": ("PF00955", 236, 498),
"YHR065C": ("SM00490", 335, 416),
"YKL053C-A": ("PF05254", 5, 72),
"YOR349W": ("PANTHER", 353, 414)
}
che contiene per ogni dominio (riga) di tabella, esclusa l’intestazione,
come chiave la proteina corrispondente (prima colonna) e come valore le
informazioni associate (altre colonne: nome, inizio e fine del dominio).
PROVATE VOI
Esempio. break permette di interrompere il ciclo for. Ad
esempio:
percorso = input("scrivi un percorso a file: ")
righe = open(percorso).readlines()
for riga in righe:
riga = riga.strip()
print("ho letto:", riga)
if len(riga) == 0:
# se la riga e' vuota, esco dal ciclo
break
# <--- il break ci porta immediatamente QUI
legge le righe dal file indicato dall’utente, e le stampa una per una. Pero’
appena incontra una riga vuota (vedi l’if), esce dal ciclo.
Esempio. continue permette di passare all’iterazione successiva del
for. Ad esempio:
percorso = input("scrivi un percorso a file: ")
righe = open(percorso).readlines()
for riga in righe:
# <--- il continue ci riporta QUI, ma all'iterazione
# (e quindi all'elemento di righe) successivo
riga = riga.strip()
print("ho letto:", riga)
if riga[0] == ">":
print("intestazione")
continue
print("sequenza")
legge le righe del file indicato dall’utente, che supponiamo essere un
file fasta. Stampa ogni riga che incontra. Poi, se la riga e’ un’intestazione,
stampa "intestazione" ed il continue fa saltare a Python tutto cio’
che c’e’ tra il continue stesso e la fine dell’iterazione corrente del ciclo for.
In altre parole, salta all’iterazione successiva. Python riprende noncurante
l’esecuzione all’elemento successivo di righe, e riprende ad eseguire il
for.
Codice iterativo: while¶
while permette di scrivere codice che viene ripetuto finche’ una
condizione e’ vera.
La sintassi e’:
while condizione:
condizione = codice_che_fa_qualcosa_e_aggiorna_condizione()
Il codice all’interno del while viene ripetuto un numero indefinito
di volte: dipende da quanto ci mette condizione a diventare False.
Esempio. Scrivo un ciclo while che chiede all’utente se vuole
fermarsi, e continua a chiedere finche’ l’utente non risponde "si":
while input("vuoi che mi fermi? ") != "si":
print("se non rispondi 'si' non mi fermo!")
Esempio. Esattamente come con il for, posso usare continue e
break per alterare il flusso del ciclo. Ad esempio:
while True:
risposta = input("qual'e la capitale d'Italia? ")
if risposta.lower() == "roma":
print("giusto!")
break
print("riprova!")
# <--- il break ci porta QUI
print("finito")
questo codice continua a girare finche’ l’utente non risponde "roma" (con
maiuscole o minuscole, poco importa).
Riscrivo il ciclo per fare in modo che chieda all’utente se continuare o meno:
while True:
risposta = input("qual'e' la capitale d'Italia? ")
if risposta.lower() == "roma":
print("giusto!")
break # esce dal while
else:
print("doh!")
risposta = input("vuoi riprovare? ")
if risposta.lower() == "no":
print("va bene")
break # esce dal while
Esercizi¶
Scrivere un ciclo
forche:Stampi a schermo gli elementi di
range(10), uno per riga.Stampi a schermo il quadrato degli elementi di
range(10), uno per riga.Stampi a schermo la somma dei quadrati di
range(10).Stampi a schermo il prodotto degli elementi di
range(1,10).Dato il dizionario:
volume_di = { "A": 67.0, "C": 86.0, "D": 91.0, "E": 109.0, "F": 135.0, "G": 48.0, "H": 118.0, "I": 124.0, "K": 135.0, "L": 124.0, "M": 124.0, "N": 96.0, "P": 90.0, "Q": 114.0, "R": 148.0, "S": 73.0, "T": 93.0, "V": 105.0, "W": 163.0, "Y": 141.0, }che codifica il volume di ciascun aminoacido, stampi a schermo la somma dei valori.
Dato il dizionario:
volume_di = { "A": 67.0, "C": 86.0, "D": 91.0, "E": 109.0, "F": 135.0, "G": 48.0, "H": 118.0, "I": 124.0, "K": 135.0, "L": 124.0, "M": 124.0, "N": 96.0, "P": 90.0, "Q": 114.0, "R": 148.0, "S": 73.0, "T": 93.0, "V": 105.0, "W": 163.0, "Y": 141.0, }che codifica il volume di ciascun aminoacido, e la stringa FASTA:
fasta = """>1BA4:A|PDBID|CHAIN|SEQUENCE DAEFRHDSGYEVHHQKLVFFAEDVGSNKGAIIGLMVGGVV"""
stampi a schermo il volume totale della proteina (leggi: la somma dei volumi di tutti i suoi residui).
Hint. Prima conviene estrarre la sequenza vera e propria da
fasta, poi, per ciascun carattere nella sequenza (for carattere in sequenza) prendere dal dizionario il volume corrispondente e sommarlo al totale.Trovi il valore minimo della lista
[1, 25, 6, 27, 57, 12].Hint. Si veda l’esempio sopra in cui troviamo il massimo della lista. E’ sufficiente adattare la logica che decide quando aggiornare la variabile ausiliaria (e magari rinominarla da
massimo_fino_ad_oraaminimo_fino_ad_ora).Trovi sia il massimo che il minimo della lista
[1, 25, 6, 27, 57, 12].Hint. E’ necessario usare due variabili ausiliarie:
massimo_fino_ad_oraeminimo_fino_ad_ora.Data la sequenza nucleotidica:
sequenza = "ATGGCGCCCGAACAGGGA"
restituisca la lista di tutte le sue sotto-sequenze di tre nucleotidi. La soluzione deve essere:
["ATG", "GCG", "CCC", "GAA", "CAG", "GGA"]
Hint: conviene iterare sul risultato di
range(0, len(sequenza), 3)ed aggiungere man mano ogni tripletta ad una lista vuota preventivamente creata.Dato il testo (in formato FASTA):
testo = """>2HMI:A|PDBID|CHAIN|SEQUENCE PISPIETVPVKLKPGMDGPKVKQWPLTEEKIKALVEICTEMEKEGKISKI >2HMI:B|PDBID|CHAIN|SEQUENCE PISPIETVPVKLKPGMDGPKVKQWPLTEEKIKALVEICTEMEKEGKISKI >2HMI:C|PDBID|CHAIN|SEQUENCE DIQMTQTTSSLSASLGDRVTISCSASQDISSYLNWYQQKPEGTVKLLIYY >2HMI:D|PDBID|CHAIN|SEQUENCE QITLKESGPGIVQPSQPFRLTCTFSGFSLSTSGIGVTWIRQPSGKGLEWL >2HMI:E|PDBID|CHAIN|SEQUENCE ATGGCGCCCGAACAGGGAC >2HMI:F|PDBID|CHAIN|SEQUENCE GTCCCTGTTCGGGCGCCA"""
restituisca un dizionario
sequenza_diche abbia come chiavi i nomi delle sequenze cosi’ come sono scritti nelle intestazioni (il primo sara’2HMI:A, il secondo2HMI:B, etc.), e come valore la sequenza corrispondente.Il risultato dovra’ somigliare a questo:
sequenza_di = { "2HMI:A": "PISPIETVPVKLKPGMDGPKVKQW...", "2HMI:B": "PISPIETVPVKLKPGMDGPKVKQW...", # ... }Hint. Conviene prima spezzare
testonelle sue righe. Poi si puo’ iterare sulle righe cosi’ ottenute: se una riga e’ di intestazione, mi salvo il nome della sequenza corrispondente; se la riga invece e’ una sequenza, aggiorno il dizionario con il nome ottenuto alla riga sopra e la sequenza ottenuta dalla riga corrente.
Scrivere un ciclo
whileche:- Continui a chiedere all’utente di scrivere
"STOP". Se l’utente scrive"STOP"(in maiuscolo) termina, senno’ scrive all’utente"devi scriviere 'STOP'..."e continua. - Come sopra, ma deve terminare anche se l’utente risponde
"stop"in minuscolo.
- Continui a chiedere all’utente di scrivere
Che cosa stampa a schermo questo codice?
for numero in range(10): print("processo l'elemento", numero)for numero in range(10): print("processo l'elemento", numero) breakfor numero in range(10): print("processo l'elemento", numero) continuefor numero in range(10): print(numero) if numero % 2 == 0: breakfor numero in range(10): if numero % 2 == 0: break print(numero)condizione = False while condizione: print("la condizione e' vera")condizione = False while condizione: print("la condizione e' vera") condizione = Truecondizione = True while condizione: print("la condizione e' vera")numeri = range(10) i = 0 while i < len(numeri): print("all'indice", i, "c'e' l'elemento", numeri[i]) i += 1righe = [ "riga 1", "riga 2", "riga 3", "", "riga 5", "riga 6", ] for riga in righe: riga = riga.strip() if len(riga) == 0: break else: print("ho letto:", riga)
Data la tupla:
numeri = (0, 1, 1, 0, 0, 0, 1, 1, 2, 1, 2)
scrivere un ciclo che itera su
numeri, si ferma appena incontra il valore2e ne stampa a schermo la posizione.Data la tupla:
stringhe = ("000", "51", "51", "32", "57", "26")scrivere un ciclo che itera su
stringhe, si ferma appena incontra una stringa che contiene un carattere"2", e stampa a schermo posizione e valore della stringa sulla quale si e’ fermato.La soluzione e’: posizione
4, valore"32".
Codice annidato¶
Posso combinare un numero arbitrario di statement complessi (if, for e
while) usando l’indentazione, inclusi cicli innestati.
Esempio. Voglio simulare un orologio che ha due lancette: ore e minuti:
for ora in range(24):
for minuto in range(1, 60+1):
print("ora =", ora, "minuro =", minuto)
Qui all’esterno itero sulle ore, mentre all’interno itero sui minuti: ogni
volta che il for interno finisce le sue sessanta iterazioni, il for
esterno ne completa una.
Posso “estendere” l’orologio per comprendere anche i giorni dell’anno: si
tratta solo di aggiungere un for sui giorni che contenga il for delle
ore, cosi’:
for giorno in range(1, 365+1):
for ora in range(24):
for minuto in range(1, 60+1):
print(giorno, ora, minuto)
(ignorando gli anni bisestili).
Naturalmente posso “estendere” l’orologio agli anni aggiungendo un altro
for ancora piu’ esterno, etc.
Esempio. Voglio sapere se in una lista ci sono elementi ripetuti, e se ci sono in che posizioni si trovano. Partiamo dalla lista:
numeri = [5, 9, 4, 4, 9, 2]
L’idea e’ di usare due cicli for innestati per iterare sulle coppie
di elementi di numeri.
In pratica, per ciascun elemento (diciamo in posizione i) voglio
controllare se almeno uno di quelli che stanno alla sua destra (diciamo in
posizione j) e’ uguale a lui. Immagine:
+---+---+---+---+---+---+
| 5 | 9 | 4 | 4 | 9 | 2 |
+---+---+---+---+---+---+
^
i
\__________________/
i possibili valori di j
+---+---+---+---+---+---+
| 5 | 9 | 4 | 4 | 9 | 2 |
+---+---+---+---+---+---+
^ ^
i doppione!
\______________/
i possibili valori di j
+---+---+---+---+---+---+
| 5 | 9 | 4 | 4 | 9 | 2 |
+---+---+---+---+---+---+
^ ^
i doppione!
\__________/
i possibili valori di j
Scrivo:
posizioni_ripetizioni = []
for i in range(len(numeri)):
numero_in_pos_i = numeri[i]
# ho il numero in posizione i; ora lo voglio
# confrontare con quelli che lo seguono
for j in range(i + 1, len(numeri)):
numero_in_pos_j = numeri[j]
# ora confronto i due numeri
if numero_in_pos_i == numero_in_pos_j:
# sono uguali: aggiungo le loro
# posizioni alla lista
posizioni_ripetizioni.append((i, j))
print(posizioni_ripetizioni)
Okay, ho ottenuto le posizioni dei ripetizioni. Verifico stampando, per ciascuna
coppia di posizioni in posizioni_ripetizioni i valori corrispondenti:
for i, j in posizioni_ripetizioni:
numero_in_pos_i = numeri[i]
numero_in_pos_j = numeri[j]
print(numero_in_pos_i, numero_in_pos_j)
Esempio. Apro un file FASTA e ne leggo i contenuti in una lista di stringhe:
righe = open("data/prot-fasta/3J01.fasta").readlines()
Il valore di righe sara’ e’:
righe = [
">3J01:0|PDBID|CHAIN|SEQUENCE",
"AVQQNKPTRSKRGMRRSHDALTAVTSLSVDKTSGEKHLRHHITADGYYRGRKVIAK",
">3J01:1|PDBID|CHAIN|SEQUENCE",
"AKGIREKIKLVSSAGTGHFYTTTKNKRTKPEKLELKKFDPVVRQHVIYKEAKIK",
">3J01:2|PDBID|CHAIN|SEQUENCE",
"MKRTFQPSVLKRNRSHGFRARMATKNGRQVLARRRAKGRARLTVSK",
">3J01:3|PDBID|CHAIN|SEQUENCE",
# ...
]
Voglio convertire righe in un dizionario dove le chiavi sono le
intestazioni, e i valori corrispondenti sono le sequenze.
Scrivo:
# parto da un dizionario vuoto
dizionario = {}
# per ogni riga...
for riga in righe:
if riga[0] == ">":
# e' una riga di intestazione: la memorizzo
# nella variabile 'intestazione'
intestazione = riga
else:
# non e' una riga di intestazione: la
# memorizzo nella variabile 'sequenza'
sequenza = riga
# a questo punto ho sia l'intestazione (che
# ho memorizzato nella riga precedente) sia
# la sequenza (che ho memorizzato in questa
# riga): aggiorno il dizionario
dizionario[intestazione] = sequenza
# una volta scorse tutte le righe, ho finito
# di creare il mio dizionario. lo stampo
print(dizionario)
Funziona, ma c’e’ un problema.
Se guardiamo bene, in righe ci sono casi in cui la sequenza di una catena
proteica occupa piu’ righe. Ad esempio:
righe = [
# ...
">3J01:5|PDBID|CHAIN|SEQUENCE",
"MAKLTKRMRVIREKVDATKQYDINEAIALLKELATAKFVESVDVAVNLGIDARKSDQNVRGATVLPHGTGRSVRVAVFTQ",
"GANAEAAKAAGAELVGMEDLADQIKKGEMNFDVVIASPDAMRVVGQLGQVLGPRGLMPNPKVGTVTPNVAEAVKNAKAGQ",
"VRYRNDKNGIIHTTIGKVDFDADKLKENLEALLVALKKAKPTQAKGVYIKKVSISTTMGAGVAVDQAGLSASVN",
# ...
]
In questo caso il nostro codice non funziona: quando facciamo
dizionario[intestazione] = sequenza mettiamo nel dizionario solo l’ultima
riga della sequenza corrente, dimenticandoci di tutte quelle che la
precedono!
Per sistemare il codice, devo fare in modo che si ricordi di tutte le righe della sequenza che corrisponde all’intestazione corrente. Scrivo:
sequenza_di = {}
for riga in righe:
if riga[0] == ">":
intestazione = riga
else:
sequenza = riga
# qui, al posto di mettere nel dizionario la sequenza,
# metto una lista di TUTTE le righe che compongono
# la sequenza
if not intestazione in sequenza_di:
sequenza_di[intestazione] = []
sequenza_di[intestazione].append(sequenza)
L’if not ... serve per accertarsi che la lista di righe associata ad
intestazione esista, altrimenti non posso farci append().
Una alternativa e’ questa:
for riga in righe:
if riga[0] == ">":
intestazione = riga
sequenza_di[intestazione] = []
else:
sequenza = riga
sequenza_di[intestazione].append(sequenza)
In questa versione garantisco che sequenza_di[intestazione] sia una
lista ogni volta che leggo una nuova intestazione.
Assumiamo che un burlone abbia formattato in modo sbagliato il file FASTA: ha messo prima le sequenze, e poi le intestazioni corrispondenti. Esempio:
fasta_sottosopra = [
# prima sequenza e prima intestazione
"AVQQNKPTRSKRGMRRSHDALTAVTSLSVDKTSGEKHLRHHITADGYYRGRKVIAK",
">3J01:0|PDBID|CHAIN|SEQUENCE",
# seconda sequenza e seconda intestazione
"AKGIREKIKLVSSAGTGHFYTTTKNKRTKPEKLELKKFDPVVRQHVIYKEAKIK",
">3J01:1|PDBID|CHAIN|SEQUENCE",
]
Il nostro codice non funziona piu’: nel codice assumiamo che quando leggiamo una riga della sequenza, l’intestazione corrispondente sia gia’ nota. Pero’ in questo FASTA sottosopra e’ vero il contrario!
Riscriviamo il codice in modo da assumere, invece, che e’ quando otteniamo l’intestazione che gia’ conosciamo la sequenza!
Scrivo:
dizionario = {}
ultima_sequenza = []
for riga in righe:
if riga[0] == ">":
# e' una riga di intestazione, ho gia' memorizzato
# la sequenza in 'ultima_sequenza'. aggiorno il
# dizionario
intestazione = riga
dizionario[intestazione] = ultima_sequenza
# ora che ho messo il valore di 'ultima_sequenza',
# la faccio ricominciare dalla lista vuota
ultima_sequenza = []
else:
# e' una riga di sequenza, ma ancora non conosco
# l'intestazione (nel file, viene dopo!). non
# tocco il dizionario, mi limito a memorizzare
# la sequenza nella lista 'ultima_sequenza'
sequenza = riga
ultima_sequenza.append(sequenza)
print(dizionario)
Esercizi¶
Data la matrice:
n = 5 matrice = [list(range(n)) for i in range(n)]
scrivere un doppio ciclo
forche stampi a schermo tutti gli elementi dimatrice, uno per riga.Data la matrice:
n = 5 matrice = [list(range(n)) for i in range(n)]
cosa stampano i seguenti frammenti di codice?
for riga in matrice: for elemento in riga: print(elemento)somma = 0 for riga in matrice: for elemento in riga: somma = somma + elemento print(somma)for i in range(len(matrice)): riga = matrice[i] for j in range(len(riga)): elemento = riga[j] print(elemento)for i in range(len(matrice)): for j in range(len(matrice[i])): print(matrice[i][j])non_lo_so = [] for i in range(len(matrice)): for j in range(len(matrice[i])): if i == j: non_lo_so.append(matrice[i][j]) print(" ".join([str(x) for x in non_lo_so]))
Data la lista:
numeri = [8, 3, 2, 9, 7, 1, 8]
scrivere un doppio ciclo
forche stampa a schermo tutte le coppie di elementi dinumeri.Modificare la soluzione dell’esercizio sopra in modo che se la coppia
(i,j)e’ gia’ stata stampata, allora la coppia simmetrica(j,i)non venga stampata.Hint. Vedi l’esempio sopra.
Fare la stessa cosa con la lista:
stringhe = ["io", "sono", "una", "lista"]
Dato l’intervallo:
numeri = range(10)
scrivere un doppio ciclo
forche stampa a schermo solo le coppie di elementi dinumeridove il secondo elemento della coppia e’ il doppio del primo.Il risultato dovra’ essere:
0 0 1 2 2 4 ...
Data la lista:
numeri = [8, 3, 2, 9, 7, 1, 8]
scrivere un doppio ciclo
forche itera su tutte le coppie degli elementi dinumerie stampa a schermo le coppie di elementi la cui somma e’10.(E’ lecito stampare eventuali “ripetizioni”, ad esempio
8 + 2e2 + 8.)Il risultato dovra’ essere:
8 2 3 7 2 8 9 1
Hint. C’e’ un esempio che mostra come iterare sulle coppie di elementi di una lista. E’ sufficiente adattarlo.
Come sopra, ma al posto di stampare a schermo, memorizzare le coppie degli elementi la cui somma e’
10in una listalista_delle_coppie.Il risultato dovra’ essere:
>>> lista_delle_coppie [(8, 2), (3, 7), (2, 8), 9, 1)]
Date le liste:
numeri_1 = [5, 9, 4, 4, 9, 2] numeri_2 = [7, 9, 6, 2]
scrivere un doppio ciclo
forche itera sulle due liste e stampa a schermo valori e posizioni degli elementi dinumeri_1che appaiono anche innumeri_2.Il risultato dovra’ essere:
posizioni: 1, 1; valore ripetuto: 9 posizioni: 4, 1; valore ripetuto: 9 posizioni: 5, 3; valore ripetuto: 2
Come sopra, ma al posto di stampare a schermo, memorizzare le posizioni ed il valore ripetuto una lista di triple della forma
(posizione_1, posizione_2, valore_ripetuto).Data la matrice:
n = 5 matrice = [list(range(n)) for i in range(n)]
scrivere un doppio ciclo
forche trovi l’elemento piu’ grande.Hint. E’ sufficiente adattare il codice per trovare il massimo-minimo di una lista (che e’ ad una dimensione) alla matrice (che ha due dimensioni).
Data la lista di sequenze nucleotidiche:
sequenze = [ "ATGGCGCCCGAACAGGGA", "GTCCCTGTTCGGGCGCCA", ]voglio ottenere una lista che contenga, per ogni sequenza in
sequenze, la lista delle sue triplette.Hint. Si puo’ riutilizzare un esercizio precedente.
Data la lista:
numeri = [5, 9, 4, 4, 9, 2]
scrivere del codice che conta il numero di ripetizioni di ogni elemento, e metta il risultato in un dizionario. Il dizionario dovra’ somigliare a questo:
num_ripetizioni = { 5: 1, 9: 2, 4: 2, 2: 1, }Hint. Si puo’ modificare uno degli esempi sopra in modo che, invece di salvare la posizione delle ripetizioni, incrementi il numero di ripetizioni in
num_ripetizioni.Hint. Occhio che se la chiave
5nel dizionario non c’e’, non posso farenum_ripetizioni[5] += 1, perche’num_ripetizioni[5]non esiste! Vedi l’esempio sulla lettura del file FASTA.Data una lista di cluster di geni (liste), ad esempio:
gruppi = [["gene1", "gene2"], ["gene3"], [], ["gene4", "gene5"]]
scrivere un singolo ciclo che trova il gruppo piu’ grande e lo memorizza in una variabile
gruppo_piu_grande_fino_ad_ora.Hint: e’ simile a trovare il minimo/massimo di una lista di interi, ma la variabile ausiliaria deve contenere la lista piu’ lunga trovata fin’ora.
Data la lista di sequenze:
sequenze_2HMI = { "A": "PISPIETVPVKLKPGMDGPKVKQWPLTEEKI", "B": "PISPIETVPVKLKPGMDGPKVKQWPLTEEKI", "C": "DIQMTQTTSSLSASLGDRVTISCSASQDISS", "D": "QITLKESGPGIVQPSQPFRLTCTFSGFSLST", "E": "ATGGCGCCCGAACAGGGAC", "F": "GTCCCTGTTCGGGCGCCA", }scrivere un ciclo for che (iterando sulle coppie chiave-valore del dizionario) restituisca un dizionario degli istogrammi (dizionari aminoacido->numero di ripetizioni) di ciascun elemento di
sequenze_2HMI.Hint. Calcolare un istogramma richiede esso stesso un ciclo
for: quindi in totale ci si puo’ aspettare che ci siano due cicliforinnestati.Il risultato (un dizionario di dizionari) dovra’ somigliare a questo:
istogrammi = { "A": { "P": 6, "I": 3, "S": 1, #... }, "B": { "P": 6, "I": 3, "S": 1, #... }, #... "F": { "A": 1, "C": 7, "G": 6, "T": 4, } }Data la lista di stringhe:
tabella = [ "protein domain start end", "YNL275W PF00955 236 498", "YHR065C SM00490 335 416", "YKL053C-A PF05254 5 72", "YOR349W PANTHER 353 414", ]scrivere del codice che prenda i nomi delle colonne dalla prima riga di
tabellae:per ciascuna riga compili un dizionario di questo tipo:
dizionario = { "protein": "YNL275W", "domain": "PF00955", "start": "236", "end":, "498" }appenda il dizionario ad una lista.
Date:
alfabeto_min = "abcdefghijklmnopqrstuvwxyz" alfabeto_mai = alfabeto_min.upper()
scrivere un ciclo (
forowhile) che, partendo da un dizionario vuoto, inserisca tutte le coppie chiave-valore:"a": "A", "b": "B", ...
cioe’ che mappi dal carattere i-esimo di
alfabeto_minal carattere i-esimo dialfabeto_mai.Poi usare il dizionario cosi’ costruito per implementare un ciclo
forche, data una stringa arbitraria, ad esempio:stringa = "sono una stringa"
abbia lo stesso effetto di
stringa.upper().Scrivere un modulo che chiede all’utente il percorso a due file di testo, e stampa a schermo le righe dei due file, una per una, appaiate: le righe del primo file vanno stampate sulla sinistra, le righe del secondo sulla destra.
Se il primo file contiene:
prima riga seconda riga
ed il secondo:
ACTG GCTA
il risultato deve essere:
prima riga ACTG seconda riga GCTA
Hint. Attenzione che i due file potrebbero avere lunghezze diverse. In questo caso (opzionalmente) le righe “mancanti” vanno stampate come se fossero righe vuote.
Scrivere un modulo che, dato il file
data/dna-fasta/fasta.1:- Legga i contenuti del file FASTA in un dizionario.
- Calcoli quante volte ogni nucleotide appare in ciascuna sequenza.
- Calcoli il GC-content della sequenza.
- Calcoli la AT/GC-ratio della sequenza.
Statement Complessi (Soluzioni)¶
if (Soluzioni)¶
Soluzione:
numero = int(input("scrivi un numero: ")) if numero % 2 == 0: print("pari") else: print("dispari")Uso
elseperche’ pari e dispari sono le uniche due possibilita’.Volendo, posso esplicitare la terza possibilita’, cioe’ il caso in cui
numeronon e’ ne’ pari ne’ dispari, cosi’:if numero % 2 == 0: print("pari") elif numero % 2 == 1: print("dispari") else: print("impossibile!")ma il codice nell’
elsenon verra’ eseguito per nessun valore dinumero!Visto che le due possibilita’ (
numeroe’ pari,numeroe’ dispari) sono mutualmente esclusive, posso anche permettermi di scrivere:if numero % 2 == 0: print("pari") if numero % 2 == 1: print("dispari")perche’ anche in assenza dell’
else, uno e solo uno dei dueifpuo’ essere eseguito.Soluzione:
numero = float(input("scrivi un razionale: ")) if numero >= -1 and numero <= 1: print("okay")Non servono ne’
elif(c’e’ una sola condizione) ne’else(se la condizione e’ falsa, non devo fare niente).Soluzione:
risposta = input("scrivi due numeri separati da spazio: ") parole = risposta.split() numero1 = int(parole[0]) numero2 = int(parole[1]) if numero1 > numero2: print("primo") elif numero2 > numero1: print("secondo") else: print("nessuno dei due")In alternativa:
risposta = input("scrivi due numeri separati da spazio: ") numeri = [int(parola) for parola in risposta.split()] if numeri[0] > numeri[1]: print("primo") elif numeri[0] < numeri[1]: print("secondo") else: print("nessuno dei due")Soluzione:
oroscopo_di = { "gennaio": "fortuna estrema", "febbraio": "fortuna galattica", "marzo": "fortuna incredibile", "aprile": "ultra-fortuna", } mese = input("dimmi il tuo mese di nascita: ") if mese in oroscopo_di: print(oroscopo_di[mese]) else: print("non disponibile")Soluzione:
percorso = input("scrivi il percorso: ") righe = open(percorso, "r").readlines() if len(righe) == 0: print("vuoto") elif len(righe) < 100: print("piccolo", len(righe)) elif len(righe) < 1000: print("medio", len(righe)) else: print("grande", len(righe))Si noti che non e’ necessario specificare per intero le condizioni: nel codice abbrevio
100 < len(righe) < 1000conlen(righe) < 1000. Me lo posso permettere perche’ quandolen(righe)e’ minore di100eseguo il primoelif: il secondoelifnon viene neanche considerato.Soluzione:
punto1 = [float(parola) for parola in input("scrivi tre coordinate: ").split()] punto2 = [float(parola) for parola in input("scrivi tre coordinate: ").split()] if punto1[0] >= 0 and punto1[1] >= 0 and punto1[2] >= 0 and \ punto2[0] >= 0 and punto2[1] >= 0 and punto2[2] >= 0: diff_x = punto1[0] - punto2[0] diff_y = punto1[1] - punto2[1] diff_z = punto1[2] - punto2[2] print("la distanza e'", (diff_x**2 + diff_y**2 + diff_z**2)**0.5)Si noti che il
printe’ dentro l’if.Soluzione: sappiamo che
numeroe’ un intero arbitrario (puo’ essere qualunque intero deciso dall’utente). Il codice che ci interessa e’ questo:if numero % 3 == 0: print("divide 3!") elif numero % 3 != 0: print("non divide 3!") else: print("boh")L’
if, l’elife l’elseformano una catena: solo uno tra loro viene eseguito.- L’
ifviene eseguito se e solo senumeroe’ divisibile per tre. - L’
elifviene eseguito se e solo se l’ifprecedente non viene eseguito e senumeronon e’ divisibile per tre. - L’
elseviene eseguito quando ne’ l’ifne’ l’elifvengono eseguito.
Visto che non ci sono numeri che non siano ne’ divisibili ne’ non-divisibili per
3, non resta alcuna altra possibilita’. O viene eseguito l’if, o viene eseguito l’elif: l’elsenon viene mai eseguito.Quindi la risposta e’ no.
- L’
Soluzione: come sopra,
numeroe’ un intero arbitrario. Il codice e’:numero = int(input("scrivi un numero: ")) if numero % 2 == 0: print("divide 2!") if numero % 3 == 0: print("divide 3!") if numero % 2 != 0 and numero % 3 != 0: print("boh")Qui non ci sono “catene” di
if,elifedelse: ci sono treifindipendenti.- Il primo
ifviene eseguito se e solo senumeroe’ divisibile per due. - Il secondo
ifviene eseguito se e solo senumeroe’ divisibile per tre. - Il terzo
ifviene eseguito se e solo senumeronon e’ divisibile ne’ per due, ne’ per tre.
Se
numeroe’ es. 6, che e’ divisibile sia per due che per tre, allora i primi dueifvengono entrambi eseguiti, mentre il terzo non viene eseguito.Se
numeroe’ es. 5, che non e’ divisibile ne’ per due ne’ per tre, allora i primi dueifnon vengono eseguiti; in compenso viene eseguito il terzo.Quindi la risposta e’ si’.
(Altri esempi: per
numero = 2viene eseguito solo il primoif, pernumero = 3solo il secondo. Si noti pero’ che non c’e’ verso di non eseguire nessuno uno dei treif.)- Il primo
Soluzione:
risposta = input("somma o prodotto?: ") if risposta == "somma": numero1 = int(input("numero 1: ")) numero2 = int(input("numero 2: ")) print("la somma e'", numero1 + numero2) elif risposta == "prodotto": numero1 = int(input("numero 1: ")) numero2 = int(input("numero 2: ")) print("il prodotto e'", numero1 * numero2)Usare un
ifo unelifnon altera l’esecuzione del programma.Posso semplificare cosi’:
risposta = input("somma o prodotto?: ") numero1 = int(input("numero 1: ")) numero2 = int(input("numero 2: ")) if risposta == "somma": print("la somma e'", numero1 + numero2) elif risposta == "prodotto": print("il prodotto e'", numero1 * numero2)
For While (Soluzioni)¶
Soluzioni:
Soluzione:
for numero in range(10): print(numero)Soluzione:
for numero in range(10): print(numero**2)Soluzione:
somma_quadrati = 0 for numero in range(10): somma_quadrati = somma_quadrati + numero**2 print(somma_quadrati)Soluzione:
prodotto = 1 # occhio che qui parto da 1! for numero in range(1,10): prodotto = prodotto * numero print(prodotto)Soluzione:
volume_di = { "A": 67.0, "C": 86.0, "D": 91.0, "E": 109.0, "F": 135.0, "G": 48.0, "H": 118.0, "I": 124.0, "K": 135.0, "L": 124.0, "M": 124.0, "N": 96.0, "P": 90.0, "Q": 114.0, "R": 148.0, "S": 73.0, "T": 93.0, "V": 105.0, "W": 163.0, "Y": 141.0, } somma_volumi = 0 for volume in volume_di.values(): somma_volumi = somma_volumi + volume print(somma_volumi)Soluzione:
volume_di = { "A": 67.0, "C": 86.0, "D": 91.0, "E": 109.0, "F": 135.0, "G": 48.0, "H": 118.0, "I": 124.0, "K": 135.0, "L": 124.0, "M": 124.0, "N": 96.0, "P": 90.0, "Q": 114.0, "R": 148.0, "S": 73.0, "T": 93.0, "V": 105.0, "W": 163.0, "Y": 141.0, } fasta = """>1BA4:A|PDBID|CHAIN|SEQUENCE DAEFRHDSGYEVHHQKLVFFAEDVGSNKGAIIGLMVGGVV""" # estraggo la sequenza sequenza = fasta.split("\n")[1] somma_volumi = 0 # per ciascun carattere nella sequenza... for aa in sequenza: volume_di_aa = volume_di[aa] somma_volumi = somma_volumi + volume_di_aa print(somma_volumi)Soluzione: adatto il codice dell’esempio sopra:
lista = [1, 25, 6, 27, 57, 12] minimo_fino_ad_ora = lista[0] for numero in lista[1:]: if numero < minimo_fino_ad_ora: minimo_fino_ad_ora = numero print("il minimo e':", minimo_fino_ad_ora)Soluzione: combino l’esempio e l’esercizio sopra:
lista = [1, 25, 6, 27, 57, 12] massimo = lista[0] minimo = lista[0] for numero in lista[1:]: if numero > massimo: massimo = numero if numero < minimo: minimo = numero print("minimo =", minimo, "massimo =", massimo)Soluzione:
range(0, len(sequenza), 3)restituisce[0, 3, 6, 9, ...], che sono le posizioni di inizio delle varie triplette.E’ sufficiente scrivere:
sequenza = "ATGGCGCCCGAACAGGGA" # parto da una lista vuota triplette = [] for pos_inizio in range(0, len(sequenza), 3): tripletta = sequenza[pos_inizio:pos_inizio+3] triplette.append(tripletta) print(triplette)Soluzione:
testo = """>2HMI:A|PDBID|CHAIN|SEQUENCE PISPIETVPVKLKPGMDGPKVKQWPLTEEKIKALVEICTEMEKEGKISKI >2HMI:B|PDBID|CHAIN|SEQUENCE PISPIETVPVKLKPGMDGPKVKQWPLTEEKIKALVEICTEMEKEGKISKI >2HMI:C|PDBID|CHAIN|SEQUENCE DIQMTQTTSSLSASLGDRVTISCSASQDISSYLNWYQQKPEGTVKLLIYY >2HMI:D|PDBID|CHAIN|SEQUENCE QITLKESGPGIVQPSQPFRLTCTFSGFSLSTSGIGVTWIRQPSGKGLEWL >2HMI:E|PDBID|CHAIN|SEQUENCE ATGGCGCCCGAACAGGGAC >2HMI:F|PDBID|CHAIN|SEQUENCE GTCCCTGTTCGGGCGCCA""" # prima di tutto rompo il testo in righe righe = testo.split("\n") # creo il dizionario dove metto il risultato voluto sequenza_di = {} # ora posso iterare sulle varie righe for riga in righe: if riga[0] == ">": # se la riga e' un'intestazione, estraggo il nome # della sequenza nome = riga.split("|")[0] else: # altrimenti, e' la sequenza vera a propria. il # nome l'ho ricavato nell'iterazione precedente # (che corrisponde alla riga sopra nel file FASTA) # quindi lo posso usare per aggiornare il dizionario sequenza_di[nome] = riga print(sequenza_di)
Soluzioni:
Soluzione:
while input("scrivi 'STOP': ") != "STOP": print("devi scrivere 'STOP'...")Soluzione:
while input("scrivi stop: ").lower() != "stop": print("devi scrivere stop...")
Soluzioni:
- Soluzione: tutti i numeri in
range(10). - Soluzione: il numero
0. Ilbreakinterrompe immediatamente ilfor. - Soluzione: tutti i numeri in
range(10). Ilcontinuesalta all’iterazione successiva, cosa che Python fa automaticamente quando finisce il corpo del ciclofor. Visto checontinuein questo caso si trova proprio alla fine del corpo del ciclofor, e come se non ci fosse. - Soluzione: il numero
0. Nella primissima iterazione, quandonumerovale0, prima Python esegueprint(numero), che stampa appunto0; poi l’ifviene eseguito, e cosi’ ilbreakche contiene, che fa interrompere immediatamente ilfor. - Soluzione: niente. Nella primissima iterazione, quando
numerovale0, l’ifviene eseguito e cosi’ ilbreakche contiene, che fa interrompere immediatamente ilfor. Ilprintnon viene mai eseguito. - Soluzione: niente. Il corpo del
whilenon viene mai eseguito, la condizione e’False! - Soluzione: niente. Visto che il corpo del
whilenon viene mai eseguito (la condizione e’False!), la rigacondizione = Truenon viene mai eseguita. - Soluzione:
"la condizione e' vera"un numero indefinito di volte. Visto che la condizione e’ sempreTrue, ilwhilenon finisce mai di iterare! - Soluzione: dieci stringhe della forma
"all'indice 0 c'e' l'elemento 0","all'indice 1 c'e' l'elemento 1", etc. - Soluzione: tutti gli elementi di
righe(processati dastrip()) che vengono prima della prima riga vuota, vale a dire"riga 1","riga 2"e"riga 3". Appenarigavale""(il quarto elemento dirighe) l’ifviene eseguito, e con esso ilbreak, che interrompe il ciclo. Si noti che la quarta riga non viene stampata.
- Soluzione: tutti i numeri in
Soluzione:
numeri = (0, 1, 1, 0, 0, 0, 1, 1, 2, 1, 2) for i in range(len(numeri)): numero_in_pos_i = numeri[i] if numero_in_pos_i == 2: print("la posizione e'", i) breakSoluzione:
stringhe = ("000", "51", "51", "32", "57", "26") for i in range(len(stringhe)): stringa_in_pos_i = stringhe[i] if "2" in stringa_in_pos_i: print("posizione =", i, "valore =", stringa_in_pos_i) break
Codice annidato (Soluzioni)¶
Soluzione:
n = 5 matrice = [list(range(n)) for i in range(n)] for riga in matrice: for elemento in riga: print(elemento)Soluzione:
- Tutti gli elementi della matrice.
- La somma di tutti gli elementi della matrice.
- Di nuovo tutti gli elementi della matrice.
- Di nuovo tutti gli elementi della matrice.
- La lista degli elementi sulla diagonale.
Uso due cicli
forper iterare sulle coppie di elementi:numeri = [8, 3, 2, 9, 7, 1, 8] for numero_1 in numeri: for numero_2 in numeri: print(numero_1, numero_2)E’ molto simile all’esempio dell’orologio!
Scrivo:
numeri = [8, 3, 2, 9, 7, 1, 8] coppie_gia_stampate = [] for i in range(len(numeri)): for j in range(len(numeri)): coppia = (numeri[i], numeri[j]) # controllo se ho gia' stampato la coppia simmetrica if (coppia[1], coppia[0]) in coppie_gia_stampate: continue # se arrivo qui vuol dire che non ho gia' stampato la coppia # simmetrica (altrimenti avrei fatto `continue`), quindi stampo # la coppia; poi aggiorno coppie_gia_stampate print(coppia) coppie_gia_stampate.append(coppia)Come sopra.
Soluzione:
numeri = range(10) for elemento_1 in numeri: for elemento_2 in numeri: if 2 * elemento_1 == elemento_2: print(elemento_1, elemento_2)Soluzione:
numeri = [8, 3, 2, 9, 7, 1, 8] for elemento_1 in numeri: for elemento_2 in numeri: if elemento_1 + elemento_2 == 10: print(elemento_1, elemento_2)Soluzione:
numeri = [8, 3, 2, 9, 7, 1, 8] # parto da una lista vuota lista_delle_coppie = [] for elemento_1 in numeri: for elemento_2 in numeri: if elemento_1 + elemento_2 == 10: # aggiorno la lista con append() lista_delle_coppie.append((elemento_1, elemento_2)) # stampo la lista che ho appena costruito print(lista_delle_coppie)Soluzione:
numeri_1 = [5, 9, 4, 4, 9, 2] numeri_2 = [7, 9, 6, 2] # qui itero sulla *prima* lista for i in range(len(numeri_1)): numero_in_pos_i = numeri_1[i] # qui itero sulla *seconda* lista for j in range(len(numeri_2)): numero_in_pos_j = numeri_2[j] if numero_in_pos_i == numero_in_pos_j: print("posizioni:", i, j, "; valore ripetuto:", numero_in_pos_i)Soluzione:
numeri_1 = [5, 9, 4, 4, 9, 2] numeri_2 = [7, 9, 6, 2] # parto da una lista vuota lista_delle_triplette = [] # qui itero sulla *prima* lista for i in range(len(numeri_1)): numero_in_pos_i = numeri_1[i] # qui itero sulla *seconda* lista for j in range(len(numeri_2)): numero_in_pos_j = numeri_2[j] if numero_in_pos_i == numero_in_pos_j: # al posto di stampare, aggiorno la lista lista_delle_triplette.append((i, j, numero_in_pos_i)) # stampo la lista che ho appena costruito print(lista_delle_triplette)Soluzione:
n = 5 matrice = [list(range(n)) for i in range(n)] # inizializzo con il primo elemento (un qualunque altro elemento # andrebbe comunque bene) max_elemento_fino_ad_ora = matrice[0][0] # itero... for riga in matrice: for elemento in riga: # se trovo un elemento piu' grande di max_elemento_fino_ad_ora, # aggiorno quest'ultimo if elemento > max_elemento_fino_ad_ora: max_elemento_fino_ad_ora = elemento print(max_elemento_fino_ad_ora)Soluzione:
sequenze = [ "ATGGCGCCCGAACAGGGA", "GTCCCTGTTCGGGCGCCA", ] # parto da una lista vuota risultato = [] # itero... for sequenza in sequenze: # spezzo la sequenza corrente in triplette triplette = [] for i in range(0, len(sequenza), 3): triplette.append(sequenza[i:i+3]) # appendo (*non* extend()!!!) le triplette # ottenute alla lista risultato risultato.append(triplette) # stampo la lista che ho appena costruito print(risultato)Soluzione:
numeri = [5, 9, 4, 4, 9, 2] num_ripetizioni = {} for numero in numeri: if not numero in num_ripetizioni: num_ripetizioni[numero] = 1 else: num_ripetizioni[numero] += 1o in alternativa:
numeri = [5, 9, 4, 4, 9, 2] num_ripetizioni = {} for numero in numeri: if not numero in num_ripetizioni: num_ripetizioni[numero] = 0 num_ripetizioni[numero] += 1oppure, sfruttando
count():numeri = [5, 9, 4, 4, 9, 2] num_ripetizioni = {} for numero in numeri: if not numero in num_ripetizioni: num_ripetizioni[numero] = numeri.count(numero)Si noti che in quest’ultima variante, l’
if(ma non il suo “contenuto”!) e’ opzionale.Warning
Nella formulazione originale, l’esercizio richiedeva di usare due cicli
forinnestati. Una possibile soluzione a questa versione dell’esercizio e’ la seguente:numeri = [5, 9, 4, 4, 9, 2] num_ripetizioni = {} for numero in numeri: if numero in num_ripetizioni: continue else: num_ripetizioni[numero] = 0 for numero_2 in numeri: if numero == numero_2: num_ripetizioni[numero] += 1Una versione meno “ottimizzata”:
numeri = [5, 9, 4, 4, 9, 2] num_ripetizioni = {} for numero in numeri: num_ripetizioni[numero] = 0 for numero_2 in numeri: if numero == numero_2: num_ripetizioni[numero] += 1Soluzione:
gruppi = [["gene1", "gene2"], ["gene3"], [], ["gene4", "gene5"]] # inizializzo con il primo gruppo gruppo_piu_grande_fino_ad_ora = gruppi[0] # itero... for gruppo in gruppi[1:]: if len(gruppo) > len(gruppo_piu_grande_fino_ad_ora): gruppo_piu_grande_fino_ad_ora = gruppo print(gruppo_piu_grande_fino_ad_ora)Soluzione:
sequenze_2HMI = { "A": "PISPIETVPVKLKPGMDGPKVKQWPLTEEKI", "B": "PISPIETVPVKLKPGMDGPKVKQWPLTEEKI", "C": "DIQMTQTTSSLSASLGDRVTISCSASQDISS", "D": "QITLKESGPGIVQPSQPFRLTCTFSGFSLST", "E": "ATGGCGCCCGAACAGGGAC", "F": "GTCCCTGTTCGGGCGCCA", } # parto dal dizionario vuoto istogrammi = {} for chiave, sequenza in sequenze_2HMI.items(): # associo a questa chiave un istogramma vuoto istogrammi[chiave] = {} for residuo in sequenza: if not residuo in istogrammi[chiave]: istogrammi[chiave][residuo] = 1 else: istogrammi[chiave][residuo] += 1 # stampo il risultato print(istogrammi) # stampo il risultato in modo piu' leggibile for chiave, istogramma in istogrammi.items(): print(chiave) print(istogramma) print()Soluzione:
tabella = [ "protein domain start end", "YNL275W PF00955 236 498", "YHR065C SM00490 335 416", "YKL053C-A PF05254 5 72", "YOR349W PANTHER 353 414", ] # come prima cosa estraggo i nomi delle colonne dalla prima riga nomi_colonne = tabella[0].split() # parto da una lista vuota righe_come_dizionari = [] # ora itero sulle altre righe for riga in tabella[1:]: # compilo il dizionario per questa riga dizionario = {} parole = riga.split() for i in range(len(parole)): # estraggo la parola corrispondente parola = parole[i] # estraggo il nome della colonna corrispondente nome_colonna = nomi_colonne[i] # aggiorno il dizionario dizionario[nome_colonna] = parola # ho compilato il dizionario per la riga corrente, # aggiorno la lista completa righe_come_dizionari.append(dizionario) # ho finito! stampo il risultato (una riga per volta, # per renderlo un po' piu' leggibile) for riga_come_dizionario in righe_come_dizionari: print(riga_come_dizionario)Soluzione:
alfabeto_min = "abcdefghijklmnopqrstuvwxyz" alfabeto_mai = alfabeto_min.upper() # costruisco il dizionario min_to_mai = {} for i in range(len(alfabeto_min)): min_to_mai[alfabeto_min[i]] = alfabeto_mai[i] stringa = "sono una stringa" # converto la stringa caratteri_convertiti = [] for carattere in stringa: if carattere in min_to_mai: # e' un carattere alfabetico, lo devo convertire caratteri_convertiti.append(min_to_mai[carattere]) else: # non e' un carattere alfabetico, non lo converto caratteri_convertiti.append(carattere) stringa_convertita = "".join(caratteri_convertiti) print(stringa_convertita)Soluzione:
righe_1 = open(input("percorso 1: ")).readlines() righe_2 = open(input("percoros 2: ")).readlines() # devo stare attento perche' i due file possono essere di # lunghezza diversa! max_righe = len(righe_1) if len(righe_2) > max_righe: max_righe = len(righe_2) # itero sulle righe di entrambi i file for i in range(max_righe): # prendo la i-esima riga del primo file, # sempre che esista if i < len(righe_1): riga_1 = righe_1[i].strip() else: riga_1 = "" # prendo la i-esima riga del secondo file, # sempre che esista if i < len(righe_2): riga_2 = righe_2[i].strip() else: riga_2 = "" print(riga_1 + " " + riga_2)Soluzione:
# qui leggo il file fasta fasta_come_dizionario = {} for riga in open("data/dna-fasta/fasta.1").readlines(): # mi sbarazzo di eventuali a capo riga = riga.strip() if riga[0] == ">": intestazione = riga fasta_come_dizionario[intestazione] = "" else: fasta_come_dizionario[intestazione] += riga # itero sulle coppie intestazione-sequenza for intestazione, sequenza in fasta_come_dizionario.items(): print("processo", intestazione) # conto quante volte appare ogni nucleotide conta = {} for nucleotide in ("A", "C", "T", "G"): conta[nucleotide] = sequenza.count(nucleotide) print("le conte sono", conta) # calcolo il gc-content gc_content = (conta["G"] + conta["C"]) / float(len(sequenza)) print("il GC-content e'", gc_content) # calcolo il AT/GC-ratio somma_at = conta["A"] + conta["T"] somma_cg = conta["C"] + conta["G"] at_gc_ratio = float(somma_at) / float(somma_cg) print("la AT/GC-ratio e'", at_gc_ratio)
Python: Funzioni¶
Le funzioni sono blocchi di codice a cui associamo un nome.
Per definire una nuova funzione, scrivo:
def nome_funzione(argomento_1, argomento_2, ...):
# qui metto il codice che usa argomento_1, argomento_2,
# etc. per calcolare il valore della variabile risultato
return risultato
Una volta definita la funzione, la posso chiamare/invocare dal resto del codice, cosi’:
valore_ritornato = nome_funzione(valore_1, valore_2, ...)
# qui uso valore_ritornato
Esempio. Definisco una funzione che prende due argomenti (che chiamo
arbitrariamente numero1 e numero2) e ne stampa la somma:
def stampa_somma(numero1, numero2):
print("la somma e'", numero1 + numero2)
che uso cosi’:
# stampa: la somma e' 10
stampa_somma(4, 6)
# stampa: la somma e' 17
stampa_somma(5, 12)
# stampa: la somma e' 20
stampa_somma(19, 1)
Il codice qui sopra e’ del tutto equivalente a questo:
numero1 = 4
numero2 = 6
print("la somma e'", numero1 + numero2)
numero1 = 5
numero2 = 12
print("la somma e'", numero1 + numero2)
numero1 = 19
numero2 = 1
print("la somma e'", numero1 + numero2)
Warning
In stampa_somma() non c’e’ un return. Quando manca il return,
il risultato della funzione e’ sempre None:
risultato = stampa_somma(19, 1) # stampa: la somma e' 20
print(risultato) # stampa: None
Esempio. Riscrivo la funzione stampa_somma(), che stampava la somma
dei suoi argomenti, in modo che invece restituisca (con return) la
somma come risultato:
def calcola_somma(numero1, numero2):
return numero1 + numero2
Quando la chiamo succede questo:
# non stampa niente
calcola_somma(4, 6)
# non stampa niente
calcola_somma(5, 12)
# non stampa niente
calcola_somma(19, 1)
Perche’? Proviamo a riscrivere quest’ultimo codice per esteso:
numero1 = 4
numero2 = 6
numero1 + numero2
numero1 = 5
numero2 = 12
numero1 + numero2
numero1 = 19
numero2 = 1
numero1 + numero2
Qui e’ vero che effettivamente calcolo le varie somme, ma e’ anche vero
che non le stampo mai: non c’e’ nessun print!
Quello che devo fare e’ mettere il risultato di calcola_somma() in una
variabile, e poi stamparlo a parte, cosi’:
# non stampa niente
risultato = calcola_somma(19, 1)
# stampa 20
print(risultato)
(Oppure, abbreviando: print(calcola_somma(19, 1))). Scritto per esteso,
questo codice e’ equivalente a:
numero1 = 19
numero2 = 1
risultato = numero1 + numero2
print(risultato)
Ora tutto torna: faccio la somma e ne stampo il risultato.
Warning
Il codice “contenuto” in una funzione non fa niente finche’ la funzione non viene chiamata!
Se scrivo un modulo esempio.py con questo codice:
def funzione():
print("sto eseguendo la funzione!")
e lo eseguo:
python3 esempio.py
Python non stampera’ niente, perche’ la funzione non viene mai chiamata.
Se voglio che venga eseguita, devo modificare il modulo esempio.py cosi’:
def funzione():
print("sto eseguendo la funzione!")
funzione() # <-- qui chiamo la funzione
Quano lo eseguo:
python3 esempio.py
Python trova la chiamata alla funzione (l’ultima riga del modulo) ed esegue la funzione: di conseguenza, stampera’:
sto eseguendo la funzione!
Esempio. Creo una funzione fattoriale() che prende un intero n
e ne calcola il fattoriale n!, definito cosi’:
n! = 1 \times 2 \times 3 \times \ldots (n - 2) \times (n - 1) \times n
So farlo senza una funzione? Certo. Assumiamo di avere gia’ la variabile n.
Scrivo:
fattoriale = 1
for k in range(1, n + 1):
fattoriale = fattoriale * k
Bene. Come faccio a convertire questo codice in una funzione? Semplice:
def calcola_fattoriale(n):
# n contiene il valore di cui voglio calcolare il fattoriale
# qui inserisco il codice sopra
fattoriale = 1
for k in range(1, n+1):
fattoriale = fattoriale * k
# a questo punto ho calcolato il fattoriale, e lo
# posso restituire
return fattoriale
Ora sono libero di chiamare la funzione quante volte mi pare:
print(calcola_fattoriale(1)) # 1
print(calcola_fattoriale(2)) # 2
print(calcola_fattoriale(3)) # 6
print(calcola_fattoriale(4)) # 24
print(calcola_fattoriale(5)) # 120
o anche in modi piu’ complessi:
lista = [calcola_fattoriale(n) for n in range(10)]
Warning
- Il nome della funzione ed il nome degli argomenti li scegliamo noi!
Quiz. Che differenza c’e’ tra questo frammento di codice:
def calcola(somma_o_prodotto, a, b):
if somma_o_prodotto == "somma":
return a + b
elif somma_o_prodotto == "prodotto":
return a * b
else:
return 0
print(calcola("somma", 10, 10))
print(calcola("prodotto", 2, 2))
e questo?:
def f(operation, x, y):
if operation == "sum":
return x + y
elif operation == "product":
return x * y
else:
return 0
print(f("sum", 10, 10))
print(f("product", 2, 2))
Warning
- Il codice della funzione non vede le variabili esterne alla funzione: vede solo gli argomenti!
- Il codice della funzione puo’ restituire un risultato solo attraverso
return!
Quiz. Consideriamo questo codice:
def una_funzione(a, b):
somma = a + b
return somma
a = 1
b = 2
somma = 3
una_funzione(100, 100)
print(somma)
Cosa viene stampato a schermo?
Esempio. Definisco due funzioni:
def leggi_fasta(percorso):
righe = open(percorso).readlines()
dizionario = {}
for riga in righe:
if riga[0] == ">":
intestazione = riga
else:
sequenza = riga
dizionario[intestazione] = sequenza
return dizionario
def calcola_istogramma(sequenza):
istogramma = {}
for carattere in sequenza:
if not carattere in istogramma:
istogramma[carattere] = 1
else:
istogramma[carattere] += 1
return istogramma
Date le due funzioni, posso implementare un programma complesso che (1) legge un file fasta in un dizionario, (2) per ciascuna sequenza nel file fasta calcola l’istogramma dei nucleotidi, e (3) stampa ciascun istogramma a schermo:
dizionario_fasta = leggi_fasta(percorso)
for intestazione, sequenza in dizionario_fasta.items():
istogramma = calcola_istogramma(sequenza)
print(istogramma)
Esercizi¶
Data la funzione:
def funzione(arg): return argdi che tipo e’ il risultato delle seguenti chiamate?
funzione(1)funzione({"1A3A": 123, "2B1F": 66})funzione([2*x for x in range(10)])funzione(2**-2)
Data la funzione:
def addizione(a, b): return a + bdi che tipo e’ il risultato delle seguenti chiamate?
addizione(2, 2)addizione([1,2,3], [True, False])addizione("sono una", "stringa")
Creare una funzione
stampa_pari_dispari()che prende un intero e stampa a schermo"pari"se il numero e’ pari e"dispari"altrimenti.Cosa succede se scrivo:
risultato = stampa_pari_dispari(99) print(risultato)
Creare una funzione
calcola_pari_dispari()che prende un intero e restituisce la stringa"pari"se il numero e’ pari e la stringa"dispari"altrimenti.Cosa succede se scrivo:
calcola_pari_dispari(99)
Creare una funzione
controlla_alfanumerico()che prende una stringa e restituisceTruese la stringa e’ alfanumerica (contiene solo caratteri alfabetici o numerici) eFalsealtrimenti.Per controllare se un carattere e’ alfanumerico, usare
ine la stringa::"ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789".Hint. Anche i caratteri minuscoli possono essere alfanumerici!
Creare una funzione
domanda()che non prende nessun argomento, chiede all’utente un percorso ad un file e stampa a schermo i contenuti del file. (Testarla ad esempio con il filedata/aatable.)Creare una funzione
wc()che prende una stringa e restituisce una tripla (tuple) di tre valori:- Il primo elemento della coppia deve essere la lunghezza della stringa.
- Il secondo elemento deve essere il numero di a capo nella stringa.
- Il terzo elemento deve essere il numero di parole (separate da spazi o a capo) nella stringa.
Creare una funzione
stampa_dizionario()che prende un dizionario e stampa a schermo le coppie chiave-valore del dizionario formattate come da esempio sotto.Esempio: quando applico
stampa_dizionario()a:dizionario = { "arginina": 0.7, "lisina": 0.1, "cisteina": 0.1, "istidina": 0.1, }che e’ un istogramma di frequenze, il risultato deve essere:
>>> stampa_dizionario(dizionario) istidina -> 10.0% cisteina -> 10.0% arginina -> 70.0% lisina -> 10.0%
Qui l’ordine in cui vengono stampate le righe non importa.
Come sopra, ma le chiavi devono essere ordinate alfanumericamente:
>>> stampa_dizionario_ordinato(dizionario) arginina -> 70% cisteina -> 10% istidina -> 10% lisina -> 10%
Hint: conviene estrarre le chiavi del dizionario, ordinarle a parte, scorrere le chiavi ordinate e di volta in volta stampare la riga corrispondente.
Creare una funzione
crea_lista_di_fattoriali()che prende un interon, e restituisce una lista dinelementi.L’
i-esimo elemento deve essere il fattoriale dii.Ad esempio:
>>> lista = crea_lista_di_fattoriali(5) >>> print(len(lista)) 5 # 5 elementi, come richiesto >>> print(lista[0]) 1 # e' il fattoriale di 0 >>> print(lista[1]) 1 # e' il fattoriale di 1 >>> print(lista[2]) 2 # e' il fattoriale di 2 >>> print(lista[3]) 6 # e' il fattoriale di 3 >>> print(lista[4]) 24 # e' il fattoriale di 4
Hint: conviene usare la funzione
fattoriale()definita in uno degli esempi precedenti per calcolare i valori della lista.Creare una funzione
conta_carattere()che prende due stringhe, la prima che rappresenta testo e la seconda che rappresenta un carattere.La funzione deve restituire il numero di ripetizioni del carattere nel testo.
Ad esempio:
>>> print(conta_carattere("abbaa", "a")) 3 # "a" compare 3 volte >>> print(conta_carattere("abbaa", "b")) 2 # "b" compare 2 volte >>> print(conta_carattere("abbaa", "?")) 0 # "?" non compare maiCreare una funzione
conta_caratteri()che prende due stringhe, la prima che rappresenta testo e la seconda che rappresenta un tot di caratteri.La funzione deve restituire un dizionario, in cui le chiavi sono i caratteri da cercare, e il valore associato il loro numero di ripetizioni.
Ad esempio:
>>> print(conta_caratteri("abbaa", "ab?")) {"a": 3, "b": 2, "?": 0}Creare una funzione
distanza()che prende due coppie(x1,y1)e(x2,y2)di punto bidimensionali e ne restituisce la distanza Euclidea.Hint. La distanza Euclidea e’ \sqrt{(x1-x2)^2 + (y1-y2)^2}
Creare una funzione
sottostringa()che date due stringhe ritornaTruese la seconda e’ sottostringa della prima.Creare una funzione
sottostringhe_non_vuote()che data una stringa, restituisca la lista delle sue sottostringhe non vuote.Creare una funzione
conta_sottostringhe()che, date due stringhepagliaioedago, ritorni il numero di ripetizioni diagoinpagliaio.Creare una funzione
sottostringa_piu_lunga()che date due stringhe restituisca la loro sottostringa comune piu’ lunga.Hint. Si puo’ risolvere usando l’esercizio precedente!
Funzioni (Soluzioni)¶
Soluzione: lo stesso tipo del valore che gli passo! La funzione restituisce il valore dell’argomento senza toccarlo.
- un intero.
- un dizionario.
- una lista.
- un razionale.
Soluzione: la somma o concatenazione dei due argomenti. Quindi:
- un intero.
- una lista.
- una stringa.
Soluzione:
def stampa_pari_dispari(numero): if numero % 2 == 0: print("pari") else: print("dispari") stampa_pari_dispari(98) stampa_pari_dispari(99)Occhio che
stampa_pari_dispari()stampa gia’ da se’ a schermo, non e’ necessario fare:print(stampa_pari_dispari(99))
altrimenti Python stampera’:
pari None
Il
Noneviene dalprintaggiuntivo: visto chestampa_pari_dispari()non hareturn, il suo risultato e’ sempreNone. Ilprintaggiuntivo stampa proprio questoNone.Soluzione:
def calcola_pari_dispari(numero): if numero % 2 == 0: return "pari" else: return "dispari" print(calcola_pari_dispari(98)) print(calcola_pari_dispari(99))In questo caso invece, visto che non c’e’ nessun
printincalcola_pari_dispari(), e’ necessario aggiungere a mano unprintche ne stampi il risultato!Soluzione:
def controlla_alfanumerico(stringa): caratteri_alfanumerici = "ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789" alfanumerica = True for carattere in stringa: if not carattere in caratteri_alfanumerici: alfanumerica = False return alfanumerica # testo la funzione print(controlla_alfanumerico("ABC123")) print(controlla_alfanumerico("A!%$*@"))Posso anche usare
breakper interrompere il cicloforappena trovo un carattere alfanumerico (e’ impossibile che una stringa dove ho appena trovato un carattere non-alfanumerico ridiventi alfanumerica), cosi’:def controlla_alfanumerico(stringa): caratteri_alfanumerici = "ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789" alfanumerica = True for carattere in stringa: if not carattere in caratteri_alfanumerici: alfanumerica = False break # <-- esco dal for # <-- il break mi fa arrivare qui return alfanumerica # testo la funzione print(controlla_alfanumerico("ABC123")) print(controlla_alfanumerico("A!%$*@"))In alternativa, visto che quando faccio
breakarrivo direttamente alreturn, posso saltare un passaggio e fare direttamentereturn:def controlla_alfanumerico(stringa): caratteri_alfanumerici = "ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789" for carattere in stringa: if not carattere.upper() in caratteri_alfanumerici: # ho incontrato un carattere non alfanumerico # posso rispondere False return False # arrivo alla fine del for solo se non ho mai fatto `return`, il # che succede solo se la condizione dell'`if` e' sempre stata False # per tutti i caratteri: vuol dire che sono tutti caratteri alfanumerici # rispondo True return True # testo la funzione print(controlla_alfanumerico("ABC123")) print(controlla_alfanumerico("A!%$*@"))Soluzione:
def domanda(): percorso = input("scrivi un percorso: ") print(open(percorso).readlines()) # la testo domanda()Soluzione:
def wc(stringa): num_caratteri = len(stringa) num_a_capo = stringa.count("\n") num_parole = len(stringa.split()) # split rompe sia sugli spazi che sugli a-capo return (num_caratteri, num_a_capo, num_parole) # la testo print(wc("sono\nuna bella\nstringa"))Soluzione:
def stampa_dizionario(un_dizionario): # l'ordine in cui vanno stampate le righe non importa, percio' # posso usare l'ordine naturale in cui mi vengono fornite da # `items()` for chiave, valore in un_dizionario.items(): print(chiave, "->", (str(valore * 100.0) + "%")) # la testo dizionario = { "arginina": 0.7, "lisina": 0.1, "cisteina": 0.1, "istidina": 0.1, } stampa_dizionario(dizionario)Soluzione:
def stampa_dizionario_ordinato(un_dizionario): # estraggo le chiavi e le ordino chiavi_ordinate = list(un_dizionario.keys()) chiavi_ordinate.sort() # ora stampo le coppie chiave-valore in ordine for chiave in chiavi_ordinate: valore = un_dizionario[chiave] print(chiave, "->", (str(valore * 100.0) + "%")) # la testo dizionario = { "arginina": 0.7, "lisina": 0.1, "cisteina": 0.1, "istidina": 0.1, } stampa_dizionario_ordinato(dizionario)Soluzione:
# presa dall'esempio def calcola_fattoriale(n): fattoriale = 1 for k in range(1, n+1): fattoriale = fattoriale * k return fattoriale def crea_lista_di_fattoriali(n): lista_di_fattoriali = [] for i in range(n): lista_di_fattoriali.append(calcola_fattoriale(i)) return lista_di_fattoriali # la testo print(crea_lista_di_fattoriali(2)) print(crea_lista_di_fattoriali(4)) print(crea_lista_di_fattoriali(6))qui ho riutilizzato la funzione
calcola_fattoriale()definita in uno degli esempi.Soluzione:
def conta_carattere(testo, carattere_voluto): conta = 0 for carattere in testo: if carattere == carattere_voluto: conta += 1 return conta # la testo print(conta_carattere("abbaa", "a")) print(conta_carattere("abbaa", "b")) print(conta_carattere("abbaa", "?"))oppure, piu’ semplicemente, posso sfruttare
count():def conta_carattere(testo, carattere_voluto): return testo.count(carattere_voluto) # la testo print(conta_carattere("abbaa", "a")) print(conta_carattere("abbaa", "b")) print(conta_carattere("abbaa", "?"))Soluzione:
def conta_caratteri(testo, caratteri_voluti): conta = {} for carattere_voluto in caratteri_voluti: conta[carattere_voluto] = conta_carattere(testo, carattere_voluto) return conta # la testo print(conta_caratteri("abbaa", "ab?"))dove ho riutilizzato la funzione dell’esercizio precedente.
Soluzione:
def distanza(coppia1, coppia2): x1, y1 = coppia1 x2, y2 = coppia2 dx = x1 - x2 dy = y1 - y2 return (float(dx)**2 + float(dy)**2)**0.5 # la testo print(distanza((0, 0), (1, 1))) print(distanza((2, 3), (3, 2)))Soluzione:
def sottostringa(prima, seconda): return seconda in prima # la testo print(sottostringa("ACGT", "T")) print(sottostringa("ACGT", "x"))Soluzione:
def sottostringhe_non_vuote(stringa): sottostringhe = [] # tutte le possibili posizioni in cui far iniziare la sottostringa for inizio in range(len(stringa)): # tutte le poss. posizioni in cui far finire la sottostringa for fine in range(inizio + 1, len(stringa) + 1): # estraggo la sottostringa ed aggiorno la lista sottostringhe.append(stringa[inizio:fine]) return sottostringhe # la testo print(sottostringhe_non_vuote("ACTG"))Soluzione:
def conta_sottostringhe(pagliaio, ago): ripetizioni = 0 for inizio in range(len(pagliaio)): for fine in range(inizio+1, len(pagliaio)+1): # stampo quanto vale la sottostringa, per sicurezza print(inizio, fine, ":", pagliaio[inizio:fine], "==", ago, "?") # controllo se la sottostringa e' uguale ad `ago` if pagliaio[inizio:fine] == ago: print("ho trovato una ripetizione!") ripetizioni += 1 return ripetizioni # la testo print(conta_sottostringhe("ACTGXACTG", "ACTG"))Soluzione:
def sottostringa_piu_lunga(stringa1, stringa2): # riutilizzo la soluzione sopra sottostringhe1 = sottostringhe_non_vuote(stringa1) sottostringhe2 = sottostringhe_non_vuote(stringa2) # controllo tra tutte le coppie di sottostringhe # quale e' quella piu' lunga che appare sia in # stringa1 che in stringa2 piu_lunga = "" for sottostringa1 in sottostringhe1: for sottostringa2 in sottostringhe2: # se sono uguali e piu' lunghe della sottostringa # comune piu' lunga trovata fin'ora... if sottostringa1 == sottostringa2 and \ len(sottostringa1) > len(piu_lunga): # aggiorno piu_lunga = sottostringa1 return piu_lunga # la testo print(sottostringa_piu_lunga("ACTG", "GCTA")) print(sottostringa_piu_lunga("", "ACTG")) print(sottostringa_piu_lunga("ACTG", ""))
Python: Simulazione esame 1¶
Proviamo a simulare insieme una prova d’esame! in particolare stiamo simulando l’esame del 24 7 2020
TESTO¶
Scrivere un programma che
- prenda in ingresso:
- un file con annotazioni di score di artefatti in ecografie polmonari, fatte da più medici diversi.
- due indici di medici di cui confrontare le annotazioni
- per ogni coppia di score s i , s j stampi il numero di volte in cui il primo medico ha annotato un’ecografica come s i ed il secondo come s j (anche quando s i = s j )
- stampi il numero totale di volte in cui i due medici sono stati d’accordo, ed il numero di volte in cui sono stati in disaccordo
ESMPIO File in input
video_scores.csv:
Video Score M1 Score M2 Score M3 Score M4 Score M5 Score M6
1 2 1 2 3 3 2
2 1 2 1 1 1 2
3 3 3 3 3 3 1
4 3 3 3 3 3 3
ESMPIO DI OUTPUT
python agreement.py:
Inserire nome file: video_scores.csv
Indice primo medico: 0
Indice secondo medico: 4
M0 M4 Count
2 3 8
1 1 5
3 3 5
0 0 11
0 1 6
Totale accordo: 28
Totale disaccordo: 32
SUGGERIMENTI
Si possono implementare 5 funzioni separate:
- una che legga il file dati e restituisca una lista di liste di score (una per ogni video)
- una che data la lista di liste ed un indice, restituisca la lista di score associati al medico con quell’indice
- una che data la lista di liste e due indici, restituisca un dizionario che per ogni coppia di score (s i , s j ) contiene il numero di volte in cui il primo medico ha annotato con s i e il secondo con s j
- una che dato il dizonario (e gli indici dei medici per l’intestazione) stampi i conteggi delle varie coppie di score e calcoli e stampi i totali di accordo e disaccordo
- una (o un main) che realizzi il programma richiesto usando le funzioni di cui sopra
Soluzione¶
LEGGETE E RI LEGGETE la consegna per capire se è chiara
iniziamo seguendo i suggerimenti:
- suggerimento 1
- una che legga il file dati e restituisca una lista di liste di score (una per ogni video)
SEMPLICE lo abbiamo sempre fatto:
def load_file(filename): #definisco la funzione
file = open(filename,"r") #apro il file in modalità read
righe = file.readlines() #leggo le tighe
res = [] #creo una variabile contenente il risultato
for i in righe[1:]: # itero sulle righe saltando la prima
# perche è un intestazione
res.append(i.split()[1:]) # splitto la riga, e prendo tutti gli elementi
# eccetto il primo, perche è il numero del video
return(res)
E’ corretto il codice che abbiamo scritto fino ad ora? non lo so, ma posso verificarlo:
prova = load_file(filename)
print(prova)
si, funziona!
- suggerimento 2
- una che data la lista di liste ed un indice, restituisca la lista di score associati al medico con quell’indice
mmmm, che cosa ci sta chiedendo? ci chiede di creare una funzione che prenda in input la lista di liste (il file che abbiamo appena caricato con load_file), e un indice (riferito ad un medico), ci restituisca una lista contenente gli score che ha dato il medico. Quindi, se come indice abbiamo inserito 1, allora il la nostra funzione deve restituire la lista [2,1,3,3,…]
SEMPLICE:
def get_score(table,index):
scores = []
for row in table: #itero sulla ogni riga della tabella
scores.append(row[index]) #mi salvo solo i valori in posizione index
return(scores)
E’ corretto il codice che abbiamo scritto fino ad ora? non lo so, ma posso verificarlo:
prova = load_file(filename)
scores = get_score(prova,index)
print(scores)
si, funziona!
- suggerimento 3
- una che data la lista di liste e due indici, restituisca un dizionario che per ogni coppia di score (s i , s j ) contiene il numero di volte in cui il primo medico ha annotato con s i e il secondo con s j
mmmm, che cosa ci sta chiedendo? ci chiede di creare una funzione che prenda in input la lista di liste (il file che abbiamo appena caricato con load_file), e due indici (riferiti a due medici), ci restituisca un dizionario. Il dizionario deve aver come chiave la coppia degli score data dai medici, e come valore il totale delle volte in cui si è verificata questa situazione. Esempio, supponiamo che le liste degli scores dei medici m1 e m2 siano le seguenti:
Score M1 = [2,1,3,3]
Score M2 = [1,2,3,3]
allora il dizionario in output è il seguente:
diz = {
(2,1): 1,
(1,2): 1,
(3,3): 3,
}
Ora che abbiamo capito la consegna, scrivere il codice è easy :)
def get_agreement(table,m1,m2):
score_m1 = get_score(table,m1) #uso la funzione che ho fatto prima per prendere gli score del medico m1
score_m2 = get_score(table,m2) #uso la funzione che ho fatto prima per prendere gli score del medico m2
diz = dict()
for i in range(len(score_m1)): #itero sul range della lungheza degli score i.e il numero di video
key = (score_m1[i],score_m2[i]) # creo la chiave, che è una coppia di score (score di m1, score di m2)
if key in diz: # se la chiave è già presente nel dizionario, allora incremento il suo valore
diz[key] = diz[key] + 1
else: # altrimenti (se non è presente)
diz[key] = 1 # aggiungo la chiave al dizionario con valore 1
return(diz)
E’ corretto il codice che abbiamo scritto fino ad ora? non lo so, ma posso verificarlo:
prova = load_file(filename)
dizionario = get_agreement(prova,m1,m2)
print(dizionario)
si, funziona!
suggerimento 4
- una che dato il dizonario (e gli indici dei medici per l’intestazione) stampi i conteggi delle varie coppie di score e calcoli e stampi i totali di accordo e disaccordo
In sostanza qui ci sta chiedendo di stampare l’output in un formato piu leggibile (come quelle del esempio del output), e ci sta anche chiedendo di calcolare il numero di volte in cui i medici sono in accordo e quelle in cui sono in disaccordo.
semplice:
def print_agreemnt(diz,m1,m2):
tot_agree = 0 #inizializzo gli agree
tot_disagree = 0 #inizializzo i disagree
print("M%d\tM%d\tCount" %(m1,m2)) #stampo un intestazione
for i,j in diz.keys(): #itero sulle chiavi del dizionario
print(i,"\t",j,"\t",diz[(i,j)]) #stampo score di m1, score di m2, e valore
if i == j: # se sono in accordo
tot_agree = tot_agree + diz[(i,j)] # incremento il tot_agree
else: # se non sono in accordo
tot_disagree = tot_disagree + diz[(i,j)] # incremento il tot_disagree
print("Totale accordo: ",tot_agree)
print("Totale disaccordo: ",tot_disagree)
suggerimento 5
- una (o un main) che realizzi il programma richiesto usando le funzioni di cui sopra
semplice ci chiede di mettere tutto insieme:
def load_file(filename):
file = open(filename,"r")
righe = file.readlines()
res = []
for i in righe[1:]:
res.append(i.split()[1:])
return(res)
def get_score(table,index):
scores = []
for row in table:
scores.append(row[index])
return(scores)
def get_agreement(table,m1,m2):
score_m1 = get_score(table,m1)
score_m2 = get_score(table,m2)
diz = dict()
for i in range(len(score_m1)):
key = (score_m1[i],score_m2[i])
if key in diz:
diz[key] = diz[key] + 1
else:
diz[key] = 1
return(diz)
def print_agreemnt(diz,m1,m2):
tot_agree = 0
tot_disagree = 0
print("M%d\tM%d\tCount" %(m1,m2))
for i,j in diz.keys():
print(i,"\t",j,"\t",diz[(i,j)])
if i == j:
tot_agree = tot_agree + diz[(i,j)]
else:
tot_disagree = tot_disagree + diz[(i,j)]
print("Totale accordo: ",tot_agree)
print("Totale disaccordo: ",tot_disagree)
filename = input("Inserire nome file")
m1 = int(input("indice medico 1: "))
m2 = int(input("indice medico 2: "))
res = load_file(filename)
agreement = get_agreement(res,m1,m2)
print_agreemnt(agreement,m1,m2)
Python: Simulazione esame 2¶
Proviamo a simulare insieme una prova d’esame! in particolare stiamo simulando l’esame del 12 6 2020
TESTO¶
Scrivere un programma che
- prenda in ingresso un file con annotazioni di score di artefatti in ecografie polmonari, fatte da più medici diversi.
- calcoli per ogni video lo score con pi‘ănnotazioni (score di consenso)
- restituisca per ogni score il numero di video annotati con quello score di consenso
ESMPIO File in input
video_scores.csv:
Video Score M1 Score M2 Score M3 Score M4 Score M5 Score M6
1 2 1 2 3 3 2
2 1 2 1 1 1 2
3 3 3 3 3 3 1
4 3 3 3 3 3 3
ESMPIO DI OUTPUT
python majority.py:
Inserire nome file: video_scores.csv
Majority score counts
2 (19) 1 (16) 0 (16) 3 (9)
SUGGERIMENTI
Si possono implementare 5 funzioni separate:
- una che legga il file dati e restituisca per ogni video la lista di score, ignorando eventuali valori ’NC’ (non classificabile)
- una che data una lista di score restituisca lo score più frequente
- una che data le liste di score di tutti i video, calcoli per ciascuno lo score più frequente (usando la funzione precedente) e restituisca un dizionario di conteggi degli score più frequenti
- una che stampi il dizionario di score e conteggi in ordine decrescente per conteggi.
- una (o un main) che realizzi il programma richiesto usando le funzioni di cui sottostringa_piu_lunga
Soluzione¶
LEGGETE E RI LEGGETE la consegna per capire se è chiara
iniziamo seguendo i suggerimenti:
- suggerimento 1
- una che legga il file dati e restituisca per ogni video la lista di score, ignorando eventuali valori ’NC’ (non classificabile)
SEMPLICE lo abbiamo sempre fatto:
def load_scores(filename):
f = open(filename)
all_scores = []
f.readline()
for row in f: # itero su ogni riga del file in input
data = row.split() # splitto la riga
tmp = [] # uso un array temporaneo
for i in data[1:]: # per ogni numero di artefatti in data (senza l'elem in pos 0 [che è il numero video])
if i != "NC": # se i non è uguale a NC
tmp.append(int(i)) # lo converto in intero e lo appendo a tmp
all_scores.append((data[0],tmp)) #aggiungo al risultato una tupla, contenente in pos 0 il numero del video
# in pos 1 l'array di score (senza NC)
f.close() # chiudo il file
return all_scores # ritorno il risultato
E’ corretto il codice che abbiamo scritto fino ad ora? non lo so, ma posso verificarlo:
prova = load_scores(filename)
print(prova)
si, funziona!
- suggerimento 2
- una che data una lista di score restituisca lo score più frequente
mmmm, che cosa ci sta chiedendo? data una lista di scores di un determinato video, resituisce lo score piu frequente. Es data la lista:
Video 1 = [2,1,3,3,1,1,1,1,1,1,1,1,1,1,1,1,4]
la funzione ritorna 1, perche è lo score piu frequente.
SEMPLICE:
def compute_majority_score(scores):
counts = {} # inizializzo un diz
for score in scores: # itero su tutti gli scores
if not score in counts: # se score non è in count
counts[score] = 1 # lo aggiungo e ci mento valore 1
else: # altrimenti (se score è in count)
counts[score] += 1 # incremento il valore di count
max_score=-1 # inizializzo max_score a -1
max_count=0 # inizializzo max_count a 0
for (score,count) in counts.items(): # itero sul dizinario che ho creato sopra
if count > max_count: # se il conteggio è maggiore di max_count
max_score = score # aggiorno max score
max_count = count # aggiorno max count
return max_score # ritorno il valore
E’ corretto il codice che abbiamo scritto fino ad ora? non lo so, ma posso verificarlo:
file_name = "video_scores.csv"
data = load_scores(file_name)
print(data[0])
print(compute_majority_score(data[0][1]))
si, funziona!
- suggerimento 3
- una che data le liste di score di tutti i video, calcoli per ciascuno lo score più frequente (usando la funzione precedente) e restituisca un dizionario di conteggi degli score più frequenti
mmmm, che cosa ci sta chiedendo? ci chiede di calcolare un diz, che abbia come chiave il numero di scores piu frequente di ogni video, e come valore le volte che compare. Es supponiamo di avere queste liste:
Video 1 = [2,1,3,3,1,1,1,1,1,1,1,1,1,1,1,1,4]
Video 2 = [2,1,3,3,3,3,3,3,3,3,3,3,3,3,3,3,4]
Video 3 = [2,1,3,3,1,1,1,2,2,2,2,2,2,2,2,2,2]
Video 4 = [2,1,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3]
Lo score piu frequente è:
score piu freq di video 1 = 1
score piu freq di video 2 = 3
score piu freq di video 3 = 2
score piu freq di video 4 = 3
il dizionario in output è il seguente:
diz = {
2: 1,
3: 2,
1: 1,
}
Ora che abbiamo capito la consegna, scrivere il codice è easy :)
def compute_majority_counts(all_scores):
majority_counts = {}
for (video,scores) in all_scores:
majority_score = compute_majority_score(scores)
if not majority_score in majority_counts:
majority_counts[majority_score] = 1
else:
majority_counts[majority_score] += 1
return majority_counts
E’ corretto il codice che abbiamo scritto fino ad ora? non lo so, ma posso verificarlo:
filename = "video_scores.csv"
all_scores = load_scores(filename)
majority_counts = compute_majority_counts(all_scores)
print(majority_counts)
si, funziona!
suggerimento 4
- una che stampi il dizionario di score e conteggi in ordine decrescente per conteggi.
semplice:
def print_majority_counts(majority_counts):
score_list = [(count,score) for (score,count) in majority_counts.items()]
score_list.sort(reverse=True)
print("Majority score counts")
print("\t".join(["%d (%d)" %(score,count) for (count,score) in score_list]))
suggerimento 5
- una (o un main) che realizzi il programma richiesto usando le funzioni di cui sopra
semplice ci chiede di mettere tutto insieme:
def load_scores(filename):
f = open(filename)
all_scores = []
f.readline()
for row in f:
data = row.split()
all_scores.append((data[0],[int(i) for i in data[1:] if i != 'NC']))
f.close()
return all_scores
def compute_majority_score(scores):
counts = {}
for score in scores:
if not score in counts:
counts[score] = 1
else:
counts[score] += 1
max_score=-1
max_count=0
for (score,count) in counts.items():
if count > max_count:
max_score = score
max_count = count
return max_score
def compute_majority_counts(all_scores):
majority_counts = {}
for (video,scores) in all_scores:
majority_score = compute_majority_score(scores)
if not majority_score in majority_counts:
majority_counts[majority_score] = 1
else:
majority_counts[majority_score] += 1
return majority_counts
def print_majority_counts(majority_counts):
score_list = [(count,score) for (score,count) in majority_counts.items()]
score_list.sort(reverse=True)
print("Majority score counts")
print("\t".join(["%d (%d)" %(score,count) for (count,score) in score_list]))
filename = input("Inserire nome file: ")
all_scores = load_scores(filename)
majority_counts = compute_majority_counts(all_scores)
print_majority_counts(majority_counts)
Python: Simulazione esame 3¶
Proviamo a simulare insieme una prova d’esame! in particolare stiamo simulando l’esame del 13 2 2020
TESTO¶
Scrivere un programma che prenda in ingresso un file di proteine ciascuna rappresentata da
- nome (stile fasta)
- sequenza di residui
- sequenza di etichette di legame con RNA dei residui (’+’ = lega , ’-’ non lega)
estragga per ogni proteina la sua sottosequenza di legame più lunga, e stampi l’elenco di proteine e loro rispettiva sottesquenza ordinato per lunghezza della sottosequenza.
ESMPIO File in input
rbp_binding:
>1A34:A
TGDNSNVVTMIRAGSYPKVNPTPTWVRAIPFEVSVQSGIAFKVPVGSLFSANFRTDSFTSVTVMSVRAWTQLTPPVNEYSFVRLKPLFKTGDSTEEFEGRASNINTRASVGYRIPTNLRQNTVAADNVCEVRSNCRQVALVISCCFN
+---------+--------+--++++++-----------------------------------+--+-------------------------------------------------------------------------+-+----
>1A9N:B
IRPNHTIYINNMNDKIKKEELKRSLYALFSQFGHVVDIVALKTMKMRGQAFVIFKELGSSTNALRQLQGFPFYGKPMRIQYAKTDSDIISKMRG
-----+-+-++--++-++---+----------------+++++++++++-+-+---------------------+--+-+++++++++------
ESMPIO DI OUTPUT
python rbp_binding_stats.py:
inserire nome file: rbp_binding
1M90:M TSKKKRQRGSRTHGGGSHKNRRGAGHRGGRGDAGRDKHEFHN
1M90:D RQGWRRRIGNLGPWNPSRVRSTVPQQGQ
1M90:N RKGSSRRTRFNKGRRSKRMMVNR
1M90:2 TGAGTPSQGKKNTTTHTKCRRCG
1M90:C KARGTKWPNVRGVAMNAVDH
SUGGERIMENTI
Si possono implementare 5 funzioni separate:
- una che legga il file dati e restituisca una mappa proteina → sequenza proteica e sequenza di etichette di legame.
- una che data una mappa proteina → sequenza proteica e sequenza di etichette ne restituisca una proteina → sottosequenza di binding più lunga in essa contenuta (usando una funzione ausiliaria, vedi sotto)
- una funzione ausiliaria che data una coppia sequenza proteica, sequenza di etichette di legame restituisca la sottosequenza di binding più lunga
- una che data una mappa proteina → sottosequenza di binding stampi la lista di coppie proteina, sottosequenza ordinate per lunghezza della sottosequenza
- una (o un main) che realizzi il programma richiesto usando le funzioni di cui sopra
Soluzione¶
LEGGETE E RI LEGGETE la consegna per capire se è chiara
iniziamo seguendo i suggerimenti:
- suggerimento 1
- una che legga il file dati e restituisca una mappa proteina → sequenza proteica e sequenza di etichette di legame.
Quindi dobbiamo creare un diz tipo questo:
3BSO:A': ('SKISKLVIAELDFYVPRQEPMFRWMRFS', '--------------------')
3BSO:B': ('SKISKLDFYVPRQEPMFRWMRFS', '---------------++++-')
Soluzione
- def load_data(filename):
f = open(filename) prots = {} for row in f:
name = row[1:].strip() seq = f.readline().strip() bind = f.readline().strip() prots[name] = (seq,bind)f.close() return prots
E’ corretto il codice che abbiamo scritto fino ad ora? non lo so, ma posso verificarlo:
prova = load_data(filename)
print(prova)
si, funziona!
- suggerimento 2
- una che data una mappa proteina → sequenza proteica e sequenza di etichette ne restituisca una proteina → sottosequenza di binding più lunga in essa contenuta (usando una funzione ausiliaria, vedi sotto)
mmmm, che cosa ci sta chiedendo? bho, leggiamo il suggerimento 3
- suggerimento 3
- una funzione ausiliaria che data una coppia sequenza proteica, sequenza di etichette di legame restituisca la sottosequenza di binding più lunga
mmmm, che cosa ci sta chiedendo? una funzione che prenda in input una coppia (sequenza proteica, legame(+,-))e restituisca la sottosequenza piu lunga es:
# DATA LA COPPIA:
sequ = 'SKISKLDFYVPRQEPMFRWMRFS'
bind = '+++++++-----------++++-'
# la funzione ritorna
'SKISKLD'
SEMPLICE:
def longest_binding(seq, bind):
longest = ""
i = bind.find("+")
while i != -1:
j = bind.find("-", i)
if j == -1:
j = len(seq)
if j-i > len(longest):
longest = seq[i:j]
i = bind.find("+", j)
return longest
E’ corretto il codice che abbiamo scritto fino ad ora? non lo so, ma posso verificarlo:
prova = load_data(filename)
seq = prots["1A34:A"][0]
bind = prots["1A34:A"][1]
seq_piu_lunga = longest_binding(seq, bind)
print(seq_piu_lunga)
si, funziona!
Perfetto, ora possiamo passare al suggerimento 2:
- suggerimento 2
- una che data una mappa proteina → sequenza proteica e sequenza di etichette ne restituisca una proteina → sottosequenza di binding più lunga in essa contenuta (usando una funzione ausiliaria, vedi sotto)
mmmm, che cosa ci sta chiedendo?
ci chiede di calcolare un diz, che abbia come chiave il nome della proteinva, e come valore la sottosequenza piu lunga.
Es supponiamo di avere queste liste:
3BSO:A': ('SKISKLVIAELDFYVPRQEPMFRWMRFS', '-++-----------------')
3BSO:B': ('SKISKLDFYVPRQEPMFRWMRFS', '---------------++++-')
3BSO:B': ('SKISKLDFYVPRQEPMFRWMRFS', '+++++++++-------++++-')
il diz risultato è il seguente:
{
3BSO:A': 'KI',
3BSO:B': 'WMRF',
3BSO:B': 'SKISKLDF'
}
Ora che abbiamo capito la consegna, scrivere il codice è easy :)
def longest_bindings(prots):
prot_longest = {}
for prot in prots:
longest = longest_binding(prots[prot][0],prots[prot][1])
prot_longest[prot] = longest
return prot_longest
E’ corretto il codice che abbiamo scritto fino ad ora? non lo so, ma posso verificarlo:
prova = load_data(filename)
diz = longest_bindings(prot)
print(diz)
si, funziona!
suggerimento 4
- una che data una mappa proteina → sottosequenza di binding stampi la lista di coppie proteina, sottosequenza ordinate per lunghezza della sottosequenza
semplice:
def print_longest(prot_longest):
l = [(len(bind),prot,bind) for prot,bind in prot_longest.items()]
l.sort(reverse=True)
print()
print("\n".join(["%s\t%s" %(bind,prot) for length,bind,prot in l]))
suggerimento 5
- una (o un main) che realizzi il programma richiesto usando le funzioni di cui sopra
semplice ci chiede di mettere tutto insieme:
def load_data(filename):
f = open(filename)
prots = {}
for row in f:
name = row[1:].strip()
seq = f.readline().strip()
bind = f.readline().strip()
prots[name] = (seq,bind)
f.close()
return prots
def longest_binding(seq, bind):
longest = ""
i = bind.find("+")
while i != -1:
j = bind.find("-", i)
if j == -1:
j = len(seq)
if j-i > len(longest):
longest = seq[i:j]
i = bind.find("+", j)
return longest
def longest_bindings(prots):
prot_longest = {}
for prot in prots:
longest = longest_binding(prots[prot][0],prots[prot][1])
prot_longest[prot] = longest
return prot_longest
def print_longest(prot_longest):
l = [(len(bind),prot,bind) for prot,bind in prot_longest.items()]
l.sort(reverse=True)
print()
print("\n".join(["%s\t%s" %(bind,prot) for length,bind,prot in l]))
filename = "rbp_binding"
prots = load_data(filename)
print(prots)
print_longest(longest_bindings(prots))
Python: Simulazione esame 4¶
Proviamo a simulare insieme una prova d’esame! in particolare stiamo simulando l’esame del 12 1 2020
TESTO¶
Scrivere un programma che prenda in ingresso un file con un elenco di regioni conservate in UTR e un numero n e stampi:
- I primi n geni ordinati per lunghezza media delle loro regioni conservate
- I primi n cromosomi ordinati per lunghezza media delle regioni conservate nei loro geni
ESMPIO File in input
conserved_regions:
HGNC ucsc chr start end strand region.length region.sequence utr.type
SDF4 uc001adj.1 chr1 1159309 1159325 - 17 GAGGAACCGTGACTAGA 5UTR
SDF4 uc001adj.1 chr1 1159341 1159347 - 7 GTAGGTG 5UTR
DVL1 uc002quu.2 chr1 1275478 1275556 - 79 CTACCTCGGTTACATCTACGGCGGCAGAGGTGCCAGCAACGAGACGGGGTGCTACGACTACGGGTCTTTCACTACAGAA 5UTR
ESMPIO DI OUTPUT:
python regions_stats.py
Inserire nome file: conserved_regions
Inserire numero elementi: 5
Genes with longest conserved on average
RYR1 2619
DDX3X 2549
NOVA1 2074
BCL11A 1718
TSHZ3 1599
Chromosomes with longest conserved on average
chr15 181
chr2 123
chrX 122
chr10 122
chr8 105
SUGGERIMENTI
Si possono implementare 5 funzioni separate:
- una che legga il file dati e restituisca una lista con nome gene, cromosoma e lunghezza della regione conservata
- una che data la lista e un’indicazione se usare gene o cromosoma, restituisca un dizionario da gene (o da cromosoma) a elenco di lunghezze di regioni conservate per quel gene (o cromosoma)
- una che dato un dizionario chiave → lista di valori, restituisca una lista ordinata di coppie chiave, media dei suoi valori (si può usare la funzione mean del modulo statistics per calcolare la media di una lista)
- una che data una lista ordinata e un numero n, stampi le prime n coppie come da esempio
- una (o un main) che realizzi il programma richiesto usando le funzioni di cui sopra
Soluzione¶
LEGGETE E RI LEGGETE la consegna per capire se è chiara
iniziamo seguendo i suggerimenti:
- suggerimento 1
- una che legga il file dati e restituisca una lista con nome gene, cromosoma e lunghezza della regione conservata
Quindi dobbiamo creare una lista di questo tipo:
[
('SDF4', 'chr1', 17),
('SDF4', 'chr1', 7),
('DVL1', 'chr1', 79),
('CCNL2', 'chr1', 324),
...
...
]
Soluzione
FATELA VOI :)
E’ corretto il codice che abbiamo scritto fino ad ora? non lo so, ma potete verificarlo:
:)
si, funziona!
- suggerimento 2
- una che data la lista e un’indicazione se usare gene o cromosoma, restituisca un dizionario da gene (o da cromosoma) a elenco di lunghezze di regioni conservate per quel gene (o cromosoma)
mmmm, che cosa ci sta chiedendo? una funzione che prenda in input la lista che abbiamo caricato prima e una variabile che rappresenti gene o cromosoma. La funzione deve ritornare un diz tipo, se noi chiamiamo la funzione con gene:
{
'SDF4': [17, 7],
'DVL1': [79],
'CCNL2': [324, 9, 28, 47],
'MIB2': [55, 154, 37, 81, 45],
'MMP23B': [8, 14, 5, 5, 8, 7, 14, 16, 18, 7, 8],
'CDK11B': [29, 7],
}
se noi chiamiamo la funzione con cromosoma:
{
'chr1': [17, 7, 79, 324 211, 169, 18, 20, 15, 94, ....]
'chr12': [5, 38, 7, 14, 741, 29, 43, 245, ......]
}
Soluzione
FATELA VOI :)
E’ corretto il codice che abbiamo scritto fino ad ora? non lo so, ma potete verificarlo:
:)
si, funziona!
- suggerimento 3
- una che dato un dizionario chiave → lista di valori, restituisca una lista ordinata di coppie chiave, media dei suoi valori (si può usare la funzione mean del modulo statistics per calcolare la media di una lista)
mmmm, che cosa ci sta chiedendo?
ci chiede di scrivere una funzione che prenda un diz (gene -> lista di valori oppure cromosoma -> lista di valori) e restituisca una lista ordinata di coppie. Dove gli elementi della coppia sono la chiave e la media dei valori.
Es, se chiamo la funzione con il diz di cromosomi ottengo:
[
(180.72164948453607, 'chr15'),
(123.26499032882012, 'chr2'),
(121.99459459459459, 'chrX'),
(121.76344086021506, 'chr10'),
...
]
Soluzione
FATELA VOI :)
E’ corretto il codice che abbiamo scritto fino ad ora? non lo so, ma potete verificarlo:
:)
si, funziona!
suggerimento 4
- una che data una lista ordinata e un numero n, stampi le prime n coppie come da esempio
ESMPIO DI OUTPUT:
python regions_stats.py
Inserire nome file: conserved_regions
Inserire numero elementi: 5
Genes with longest conserved on average
RYR1 2619
DDX3X 2549
NOVA1 2074
BCL11A 1718
TSHZ3 1599
Chromosomes with longest conserved on average
chr15 181
chr2 123
chrX 122
chr10 122
chr8 105
suggerimento 5
- una (o un main) che realizzi il programma richiesto usando le funzioni di cui sopra
semplice ci chiede di mettere tutto insieme:
|
|
Python: Simulazione esame 5¶
Proviamo a simulare insieme una prova d’esame! in particolare stiamo simulando l’esame del 19 09 2019
TESTO¶
Scrivere un programma che prenda in ingresso un file con i dati di espressione genica binarizzata (sovraespresso o meno) di pazienti affetti da leucemia di tipo AML o ALL e
- Calcoli il coefficiente di correlazione tra i valori di espressione di ciascun gene ed una patologia di tipo AML
- Stampi la lista dei geni ordinati in base al loro coefficiente di correlazione con la patologia AML
ESMPIO File in input
gene_exp.txt:
ATP2B4,NAP1L1,MDK,PCCB,MDS1,AML
no,no,yes,no,no,no
no,no,no,yes,yes,no
no,no,no,yes,yes,no
no,no,yes,no,yes,no
no,no,no,no,yes,yes
no,yes,no,yes,yes,no
no,no,no,yes,yes,no
no,no,no,yes,yes,yes
yes,no,yes,yes,yes,no
no,no,no,yes,yes,yes
no,yes,no,yes,no,no
yes,no,no,yes,yes,yes
yes,no,yes,yes,yes,no
no,no,no,yes,yes,no
ESMPIO DI OUTPUT
python correlation2AML.py:
Inserire nome file: gene_exp.txt
gene corrcoef
MDS1 0.26
ATP2B4 0.06
PCCB -0.06
NAP1L1 -0.26
MDK -0.40
SUGGERIMENTI
Si possono implementare 5 funzioni separate:
- una che legga il file dati e restituisca l’intestazione e una matrice di dati
- una che data una matrice di dati e un indice di colonna, estragga la colonna corrispondente all’indice, convertendo i valori in numerici (0 per “no”, 1 per “yes”)
- una che dati header e matrice di dati, per ogni gene estragga la colonna corrispondente e calcoli la sua correlazione con la patologia AML (ultima colonna della matrice). La funzione restituira’ una lista di coppie gene-correlazione.
- una che data la lista di correlazioni la stampi in ordine decrescente
- una (o un main) che realizzi il programma richiesto usando le funzioni di cui sopra
NOTA Per calcolare il coefficiente di correlazione tra due liste, si può usare la funzione corrcoefdel modulo numpy
ES:
from numpy import corrcoef
a = [1,0,1,0,0,1]
b = [0,1,1,0,0,1]
corrcoef(a,b)[0,1]
# corrcoef restituisce una matrice di correlazione
# con [0,1] si prende la correlazione tra a e b
Soluzione¶
LEGGETE E RI LEGGETE la consegna per capire se è chiara
iniziamo seguendo i suggerimenti:
- suggerimento 1
- una che legga il file dati e restituisca l’intestazione e una matrice di dati
Quindi dobbiamo ritornare un due liste, una lista con le intestazioni:
['ATP2B4', 'NAP1L1', 'MDK', 'PCCB', 'MDS1', 'AML']
e una sconda lista, una matrice (lista di liste), tipo questa:
[
['no', 'no', 'yes', 'no', 'no', 'no'],
['no', 'no', 'no', 'yes', 'yes', 'no'],
['no', 'no', 'no', 'yes', 'yes', 'no'],
['no', 'no', 'yes', 'no', 'yes', 'no'],
['no', 'no', 'no', 'no', 'yes', 'yes'],
['no', 'yes', 'no', 'yes', 'yes', 'no'],
['no', 'no', 'no', 'yes', 'yes', 'no'],
['no', 'no', 'no', 'yes', 'yes', 'yes'],
['yes', 'no', 'yes', 'yes', 'yes', 'no'],
['no', 'no', 'no', 'yes', 'yes', 'yes'],
['no', 'yes', 'no', 'yes', 'no', 'no'],
['yes', 'no', 'no', 'yes', 'yes', 'yes'],
['yes', 'no', 'yes', 'yes', 'yes', 'no'],
['no', 'no', 'no', 'yes', 'yes', 'no']
]
Soluzione:
def load_data(filename):
f = open(filename)
header = f.readline().strip().split(",")
data = []
for row in f:
data.append(row.strip().split(","))
return (header, data)
E’ corretto il codice che abbiamo scritto fino ad ora? non lo so, ma posso verificarlo:
intest, matrice = load_data(filename)
print(intest)
print(matrice)
si, funziona!
- suggerimento 2
- una che data una matrice di dati e un indice di colonna, estragga la colonna corrispondente all’indice, convertendo i valori in numerici (0 per “no”, 1 per “yes”)
mmmm, che cosa ci sta chiedendo? Ci sta chiedendo di scrivere una funzione che prenda in input la matrice che abbiamo caricato al punto 1, e successivamente di trasformare i “no” in 0 e i “si” in 1.
es: data la matrice qui sotto:
[
['no', 'no', 'yes', 'no', 'no', 'no'],
['no', 'no', 'no', 'yes', 'yes', 'no'],
['no', 'no', 'no', 'yes', 'yes', 'no'],
['no', 'no', 'yes', 'no', 'yes', 'no'],
['no', 'no', 'no', 'no', 'yes', 'yes'],
['no', 'yes', 'no', 'yes', 'yes', 'no'],
['no', 'no', 'no', 'yes', 'yes', 'no'],
['no', 'no', 'no', 'yes', 'yes', 'yes'],
['yes', 'no', 'yes', 'yes', 'yes', 'no'],
['no', 'no', 'no', 'yes', 'yes', 'yes'],
['no', 'yes', 'no', 'yes', 'no', 'no'],
['yes', 'no', 'no', 'yes', 'yes', 'yes'],
['yes', 'no', 'yes', 'yes', 'yes', 'no'],
['no', 'no', 'no', 'yes', 'yes', 'no']
]
e l’indice = 1, il risultato è:
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0]
Soluzione:
def extract_column(data, i):
col = []
for row in data:
if row[i] == "yes":
col.append(1)
else:
col.append(0)
return col
E’ corretto il codice che abbiamo scritto fino ad ora? non lo so, ma posso verificarlo:
intest, matrice = load_data(filename)
a = extract_column(matrice,1)
print(a)
si, funziona!
- suggerimento 3
- una che dati header e matrice di dati, per ogni gene estragga la colonna corrispondente e calcoli la sua correlazione con la patologia AML (ultima colonna della matrice). La funzione restituira’ una lista di coppie gene-correlazione.
mmmm, che cosa ci sta chiedendo?
ci chiede di scrivere una funzione che prenda in input la matrice e l’intestazione (caricati al punto 1), successivamente per ogni colonna trasformare “yes” in 1 e “no” in 0 (usando il punto 2) e restituire la correlazione tra la colonna corrente e la colonna AML (ultima colonna), in fine ritornare i risultati, (io ho ritornato una lista di coppie, con correlazione e intestazione) Esempio:
[
(0.05504818825631804, 'ATP2B4'),
(-0.25819888974716104, 'NAP1L1'),
(-0.3999999999999999, 'MDK'),
(-0.05504818825631805, 'PCCB'),
(0.25819888974716104, 'MDS1')
]
PS per calclare la correlazione ricordatevi di importare il modulo e usare la funz corrcoef
Ora che abbiamo capito la consegna, scrivere il codice è easy :)
def compute_correlations(header, data):
label = extract_column(data, -1)
correlations = []
for i in range(len(header)-1):
name = header[i]
column = extract_column(data, i)
corr = corrcoef(label, column)[0,1]
correlations.append((corr, name))
return correlations
E’ corretto il codice che abbiamo scritto fino ad ora? non lo so, ma posso verificarlo:
intest, matrice = load_data(filename)
a = compute_correlations(intest, matrice)
print(a)
si, funziona!
suggerimento 4
- una che data la lista di correlazioni la stampi in ordine decrescente
semplice:
def print_correlations(correlations):
correlations.sort(reverse=True)
print("gene\tcorrcoef")
for (corr, name) in correlations:
print("%s\t%.2f" %(name,corr))
suggerimento 5
- una (o un main) che realizzi il programma richiesto usando le funzioni di cui sopra
semplice ci chiede di mettere tutto insieme:
from numpy import corrcoef
def load_data(filename):
f = open(filename)
header = f.readline().strip().split(",")
data = []
for row in f:
data.append(row.strip().split(","))
return (header, data)
def extract_column(data, i):
col = []
for row in data:
if row[i] == "yes":
col.append(1)
else:
col.append(0)
return col
def compute_correlations(header, data):
label = extract_column(data, -1)
correlations = []
for i in range(len(header)-1):
name = header[i]
column = extract_column(data, i)
corr = corrcoef(label, column)[0,1]
correlations.append((corr, name))
return correlations
def print_correlations(correlations):
correlations.sort(reverse=True)
print("gene\tcorrcoef")
for (corr, name) in correlations:
print("%s\t%.2f" %(name,corr))
filename=input("Inserire nome file: ")
(header, data) = load_data(filename)
correlations = compute_correlations(header, data)
print_correlations(correlations)
Video¶
Questa pagina contiene i link ai video di ogni lezione.
Laboratorio 1¶
Laboratorio 2¶
Laboratorio 3¶
Laboratorio 8¶
Laboratorio 15¶
Lab.
- Shell: Fondamentali
- Shell: Parte 1
- Python: Fondamentali
- Python: Moduli
- Python: Numeri
- Python: Stringhe
- Python: Liste
- Python: Fake Test
- Python: Dizionari
- Python: Sets
- Python: Tuple
- Python: Input-Output
- Python: Statement Complessi
- Python: Funzioni
- Python: Simulazione esame 1
- Python: Simulazione esame 2
- Python: Simulazione esame 3
- Python: Simulazione esame 4
- Python: Simulazione esame 5
- Video